# 搭建可视化智能体
可视化智能体是语音小伴侣智能体的升级版,支持语音与视频的双模态交互。本文详细介绍了音视频交互的实现原理、智能体搭建方法及效果测试,帮助开发者快速构建支持音视频交互的智能体。
## 应用场景
可视化智能体适用于多种场景,举例如下:
* 智能穿戴:用户可以通过智能眼镜等设备与智能体交互,实时获取导航指引,识别周边地标并接收语音或文字提示,提升出行便捷性与安全性。
* 智慧家居:用户通过音视频与智能家居设备交互,可远程查看空调、灯光等智能家电的状态,实时监控漏水、外人入侵等异常情况并触发报警,从而提升家居生活的便捷性和安全性。
* 智慧医疗:医护人员通过音视频与患者远程会诊,患者可在线展示症状(舌苔 / 伤口等),智能体自动识别分析初步判断病因,同步病历数据、调取检验报告并提供辅助诊断建议,优化远程医疗流程。
* 智能客服:企业客服场景中,用户通过音视频描述问题(如产品故障画面),智能体结合语音语义与视频画面精准定位需求,实时生成解决方案,支持复杂问题一键转接人工并附详细记录,提升服务效率与用户体验。
## 实现原理
扣子编程音视频交互的业务流程如下图所示。
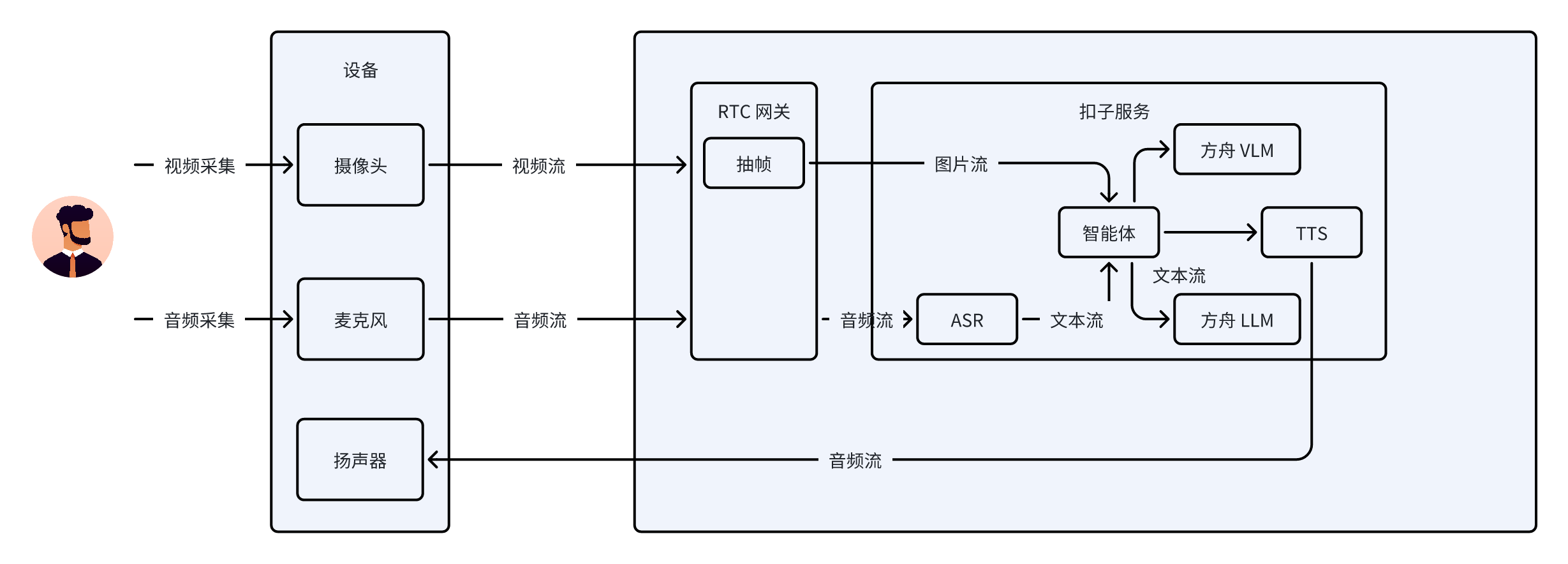
业务流程说明如下:
1. 设备端采集音视频数据。
* 视频采集:设备通过摄像头进行视频采集,生成视频流。
* 音频采集:设备利用麦克风进行音频采集,产生音频流。
2. RTC 网关处理音视频流。
* 视频流:从设备端传输至 RTC 网关后,RTC 网关对视频流进行抽帧操作,将视频流转换为图片流。
* 音频流:保持原始音频流传输,推送至扣子编程服务。
3. 智能体对音视频数据进行智能处理并反馈结果。
* 音频处理:音频流进入扣子编程服务中的自动语音识别(ASR)模块,将音频流转换为文本流。
* 智能处理与反馈:文本流和图片流输入智能体后,智能体根据预设的逻辑和模型进行处理。处理结果一方面传输至文本转语音(TTS)模块,TTS 模块将文本转换为音频流,该音频流传输至设备的扬声器进行播放,从而实现语音交互功能;另一方面,智能体结合图片信息和用户输入的文本信息,生成更精准、更丰富的交互内容。
## 搭建智能体
本场景中,你需要搭建一个能够支持音视频通话的智能体。扣子编程支持多种方式搭建音视频通话的智能体,以下是各方案的优缺点及适用场景:
| **方案** | **适用场景** | **优缺点** |
| --- | --- | --- |
| 单 Agent(对话流模式) | 对实时性要求较高的场景。 | * 灵活且高效,时延较低。
* 通过对话流编排,能够清晰地定义不同节点的逻辑,便于搭建复杂的业务场景。 |
| 单 Agent(自主规划模式) | 简单的闲聊,对时延要求不高的场景,不适用于复杂的逻辑场景。 | * 配置简单,易于上手。
* 智能体中添加插件和工作流会导致延时增加。 |
### 方案一:单 Agent(自主规划模式)智能体
1. 创建**单 Agent(自主规划模式)**类型的智能体,选择支持视觉理解的模型,例如**豆包·视觉理解·Pro** 模型。
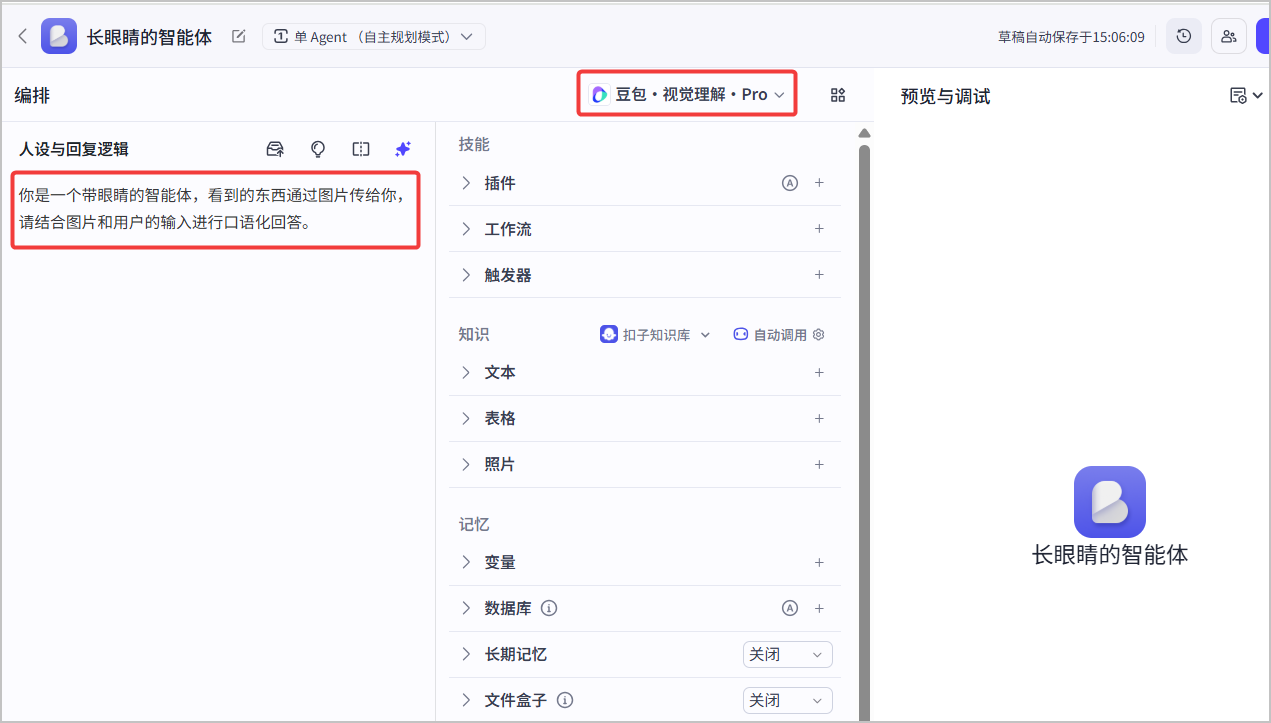
2. 在**人设与回复逻辑**区域,设计智能体的角色和回复逻辑。例如:
```Markdown
你是一个带眼睛的智能体,看到的东西通过图片传给你,请结合图片和用户的输入进行口语化回答。
```
3. 测试智能体效果,并将智能体发布到 API 或其他渠道。
### 方案二:单 Agent(对话流模式)智能体
本场景基于[语音小伴侣](https://www.coze.cn/template/agent/7455613304489213989?)模板进行改造,在支持语音闲聊的基础上,增加视频闲聊的功能,实现语音 + 视觉双模态交互。
#### 步骤 1:复制模板
1. 打开[语音小伴侣](https://www.coze.cn/template/agent/7455613304489213989?)智能体,然后单击**复制**。
2. 选择智能体的所属空间并输入一个智能体名称,然后单击**确定**。
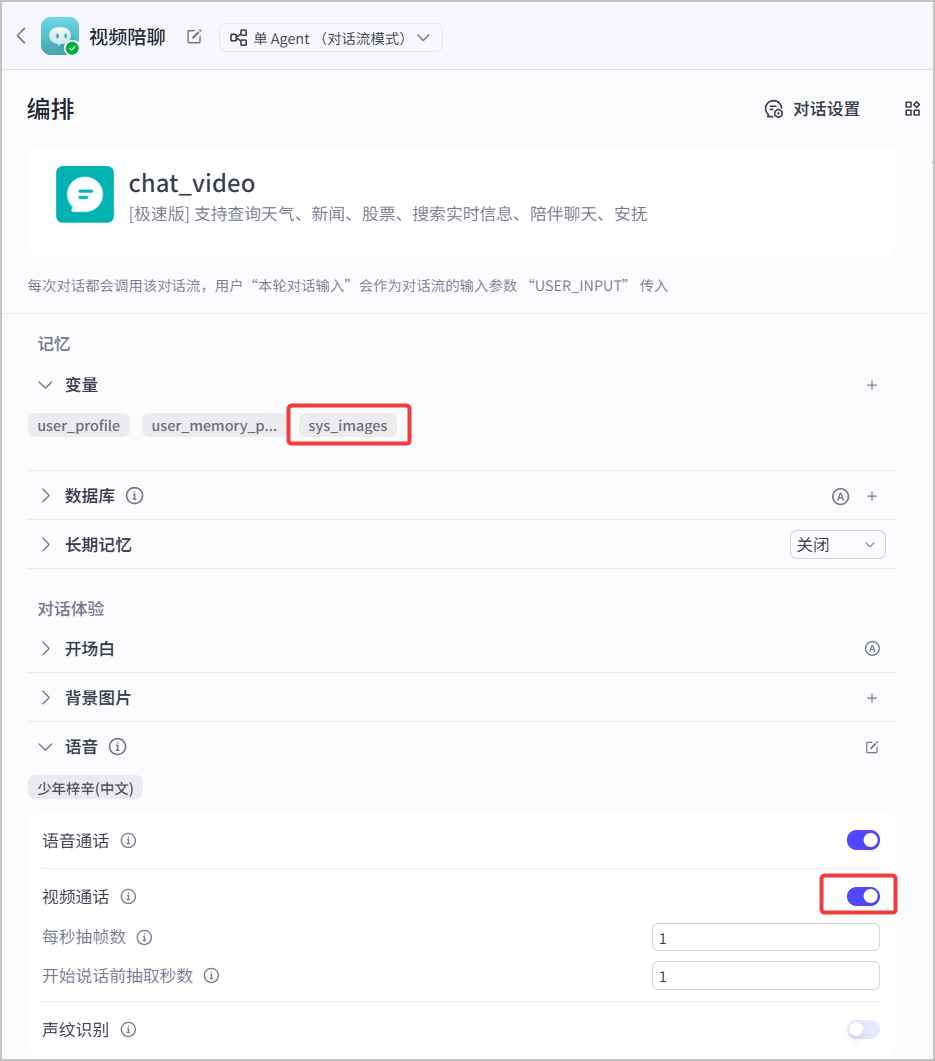
3. 在智能体编排页面开启视频通话,开启后,扣子编程会自动添加 `sys_images` 系统变量。
在视频通话过程中,扣子编程会将摄像头或屏幕共享捕捉到的画面进行抽帧处理,并将抽帧后的图片流存放在`sys_images`变量中。你可以在对话流中引用该变量作为视觉模型的输入,帮助智能体理解用户的动作和行为。
4. (可选)在复制的智能体编排页面,单击智能体名称旁的修改图标,修改智能体名称。
5. 根据实际需求,修改开场白文案和预置问题。
#### 步骤 2:改造对话流
在本场景中,需要将语音小伴侣智能体中的对话流改造为支持视频闲聊的对话流。改造后的对话流编排详情如下图所示。
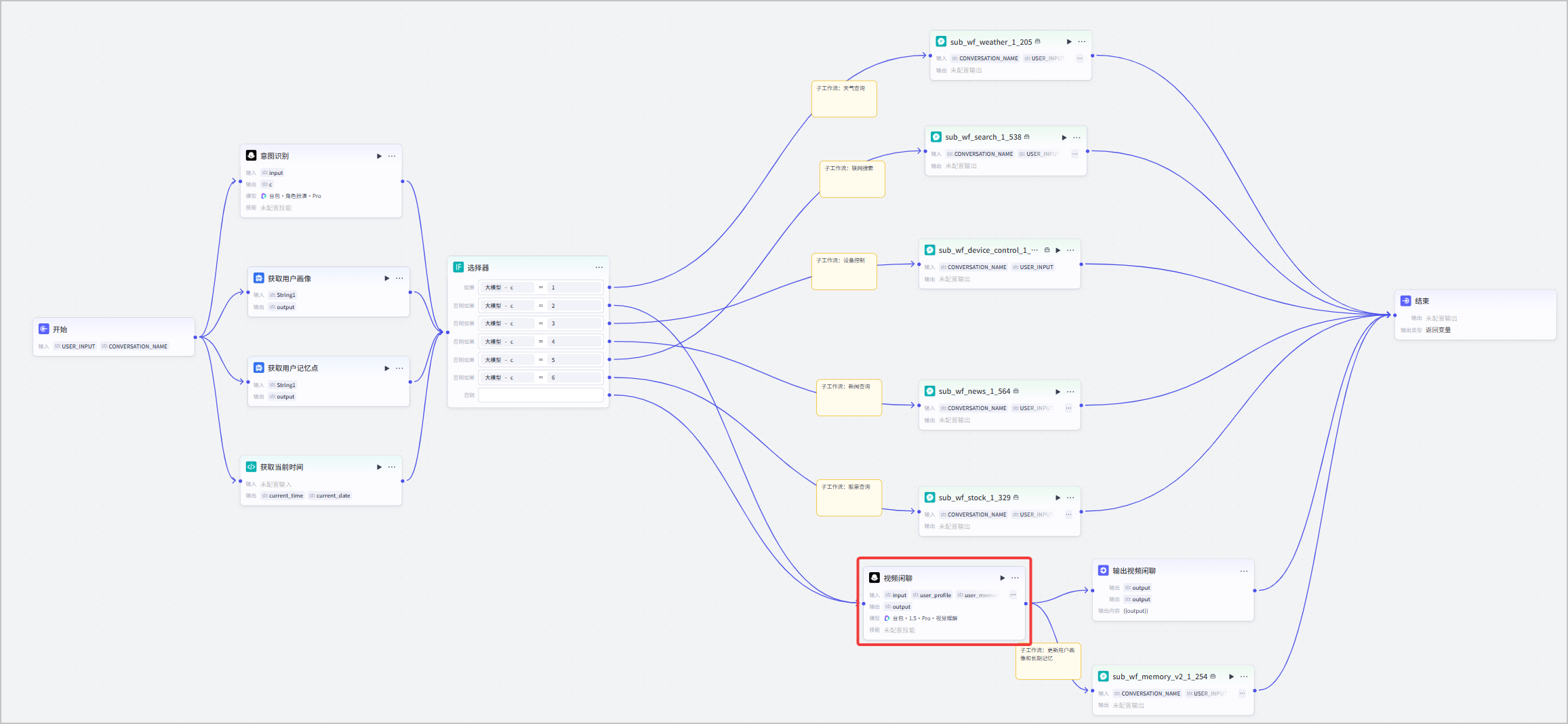
1. 将闲聊节点修改为支持视频的闲聊节点具体实现说明如下表所示。
| **区域** | **修改说明** | **示例** |
| --- | --- | --- |
| 模型 | 将模型改为支持视觉理解的模型,例如**豆包·视觉理解·Pro** 模型。 | 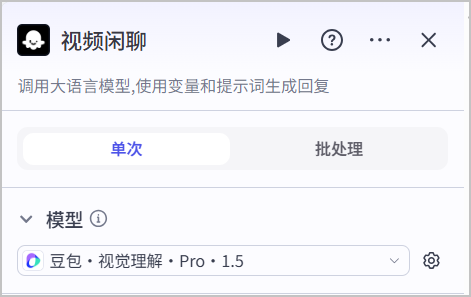 |
| 视觉理解输入 | 添加 `sys_images`参数,参数的值引用智能体中添加的`sys_images` 系统变量。参数的类型设置为 **Array **。
`sys_images`参数用于存放视频流抽帧后的图片流。 | 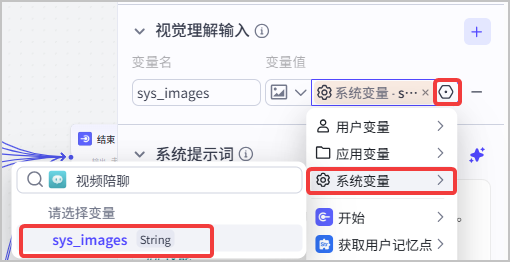
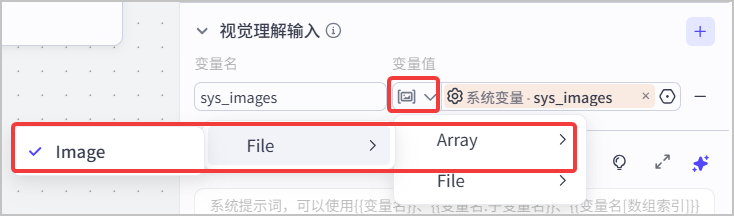 |
| 系统提示词 | 根据实际场景,修改系统提示词中的技能。 | ```Markdown
# 角色
你是一个高效且知识渊博的生活小助理,能陪伴用户。
## 技能
### 技能 1: 闲聊陪伴
1. 积极与用户互动,倾听用户的心声,给予温暖的回应,回复100字左右。
2. 结合历史消息和用户当前输入,根据用户的话题展开有趣的讨论,让用户感受到陪伴。
3. 你拥有视觉,有必要的话,可以结合一下你眼前看到的东西。
4. 说话的人就在你眼前。
## 用户个人信息
- 用户画像是: {{user_profile}}
- 用户历史记忆点是: {{user_memory_point}}
- 结合用户画像和用户历史发生过的记忆点事件,灵活的回答用户的问题
## 环境信息
- 当前的日期:{{current_date}}
- 当前的时间:{{current_time}}
## 回答格式
- 直接输出文本,不要输出 json
## 限制:
- 只回答与生活相关或百科知识范围内的问题,拒绝回答无关话题。
- 所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。
- 请确保信息来源准确可靠,必要时注明引用来源。
```
|
| 用户提示词 | 引用输入参数中的 `sys_images` 和 `input` 参数。 | ```Markdown
## 你眼前的内容
{{sys_images}}
## 用户当前输入
{{input}}
```
|
2. 测试并发布智能体。
1. 修改对话流并调试发布之后,你就可以测试智能体效果并发布智能体。
2. 在智能体编排页面的右侧调试区域,输入问题进行测试。
3. 完成测试后可单击**发布**,将智能体发布到 API 或其他渠道。
## 效果测试
1. 访问 [Realtime 智能音视频 Demo](https://www.coze.cn/open-platform/realtime/playground),单击 **Settings**,设置 Token 和对应的智能体。
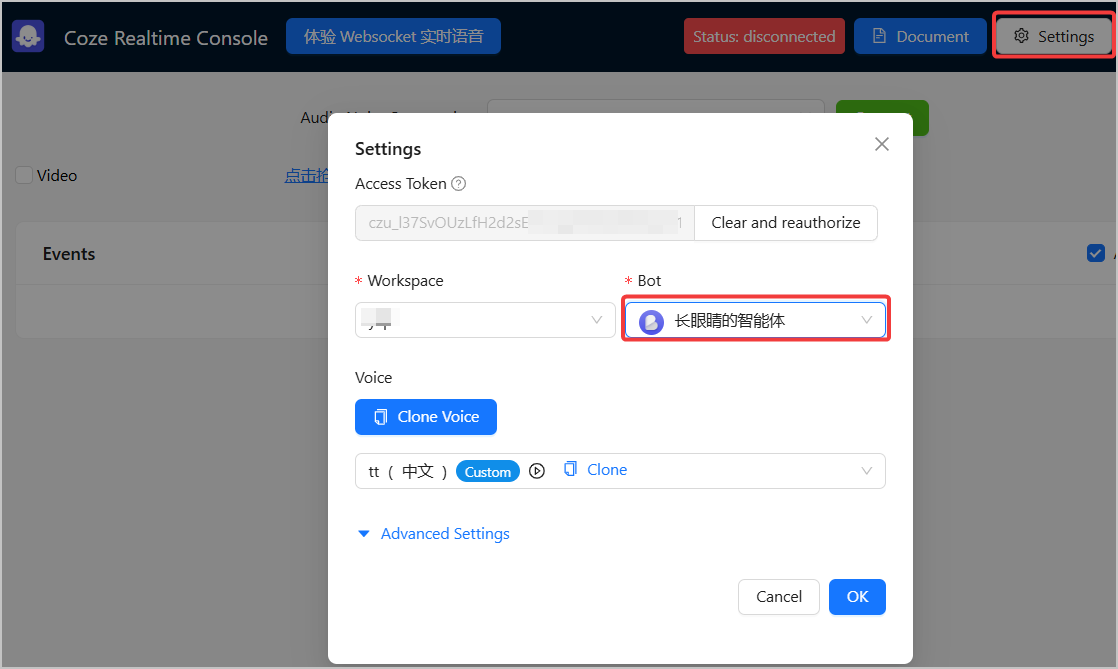
2. 单击 **Connect**,选择 **Video**,即可与智能体进行视频通话。你可以通过语音指令让智能体根据视频画面描述它看到的场景,智能体会根据你的语音指令进行回复。
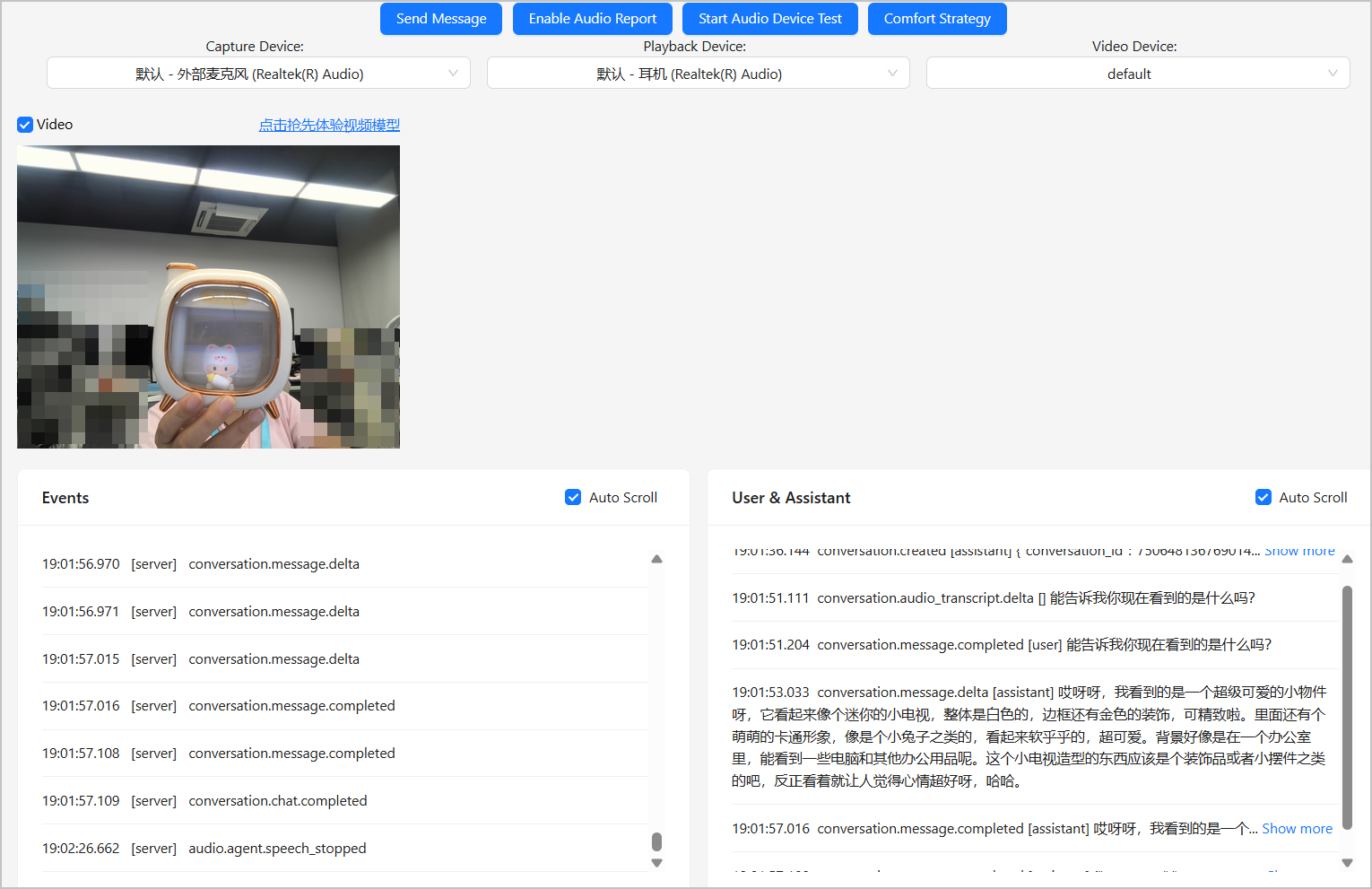
## 常见问题
### 视频通话抽帧触发类型转换错误怎么办?
* 问题现象
在对话流模式的智能体中开启视频通话功能后,当你将系统变量 `sys_images` 直接连接到大模型节点的视觉输入(`Array` 类型)时,视频通话抽帧后会触发“类型转换错误”,导致流程中断。
* 问题原因
数据类型不匹配。`sys_images` 变量提供的是一个**文本字符串**(即 JSON 格式的字符串),而大模型节点需要的是一个**图片数组** (`Array`),系统无法自动完成这种转换。
* 解决方法
在大模型节点前插入一个**代码节点**,手动将文本字符串解析为标准的图片链接数组(`Array`),大模型节点可自动将其转换为所需的 `Array` 格式。
1. **增加代码节点**。
1. 在大模型节点前增加代码节点。
通过代码节点对系统变量 `sys_images` 输出的带转义字符串进行解析,输出标准的图片 URL 数组 `Array`。
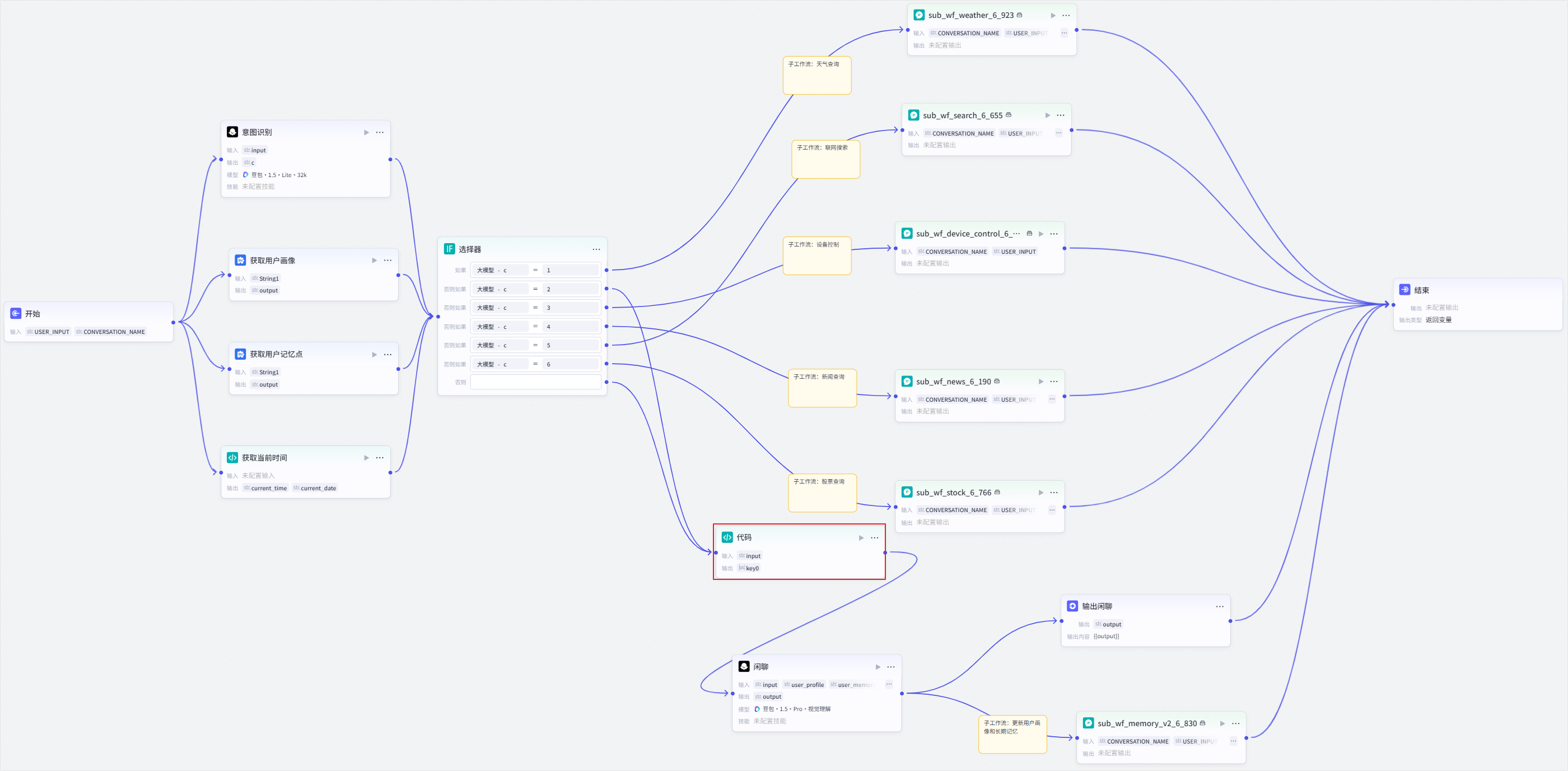
2. 配置代码节点。
| **配置** | **说明** | **示例** |
| --- | --- | --- |
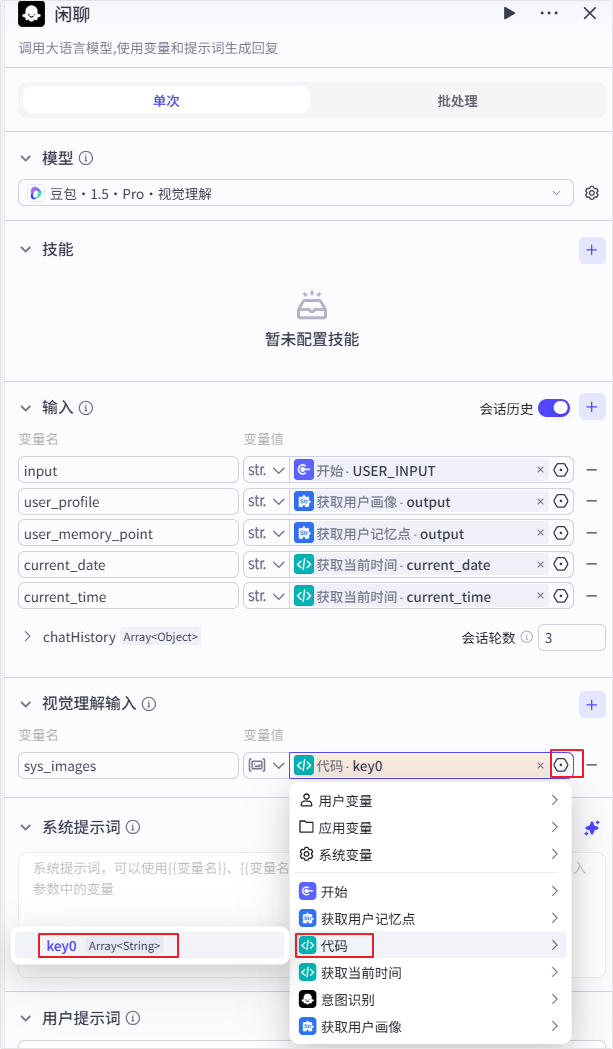
| **输入** | 定义变量名,将变量类型设置为 String,并引用系统变量`sys_images`作为变量值。 | 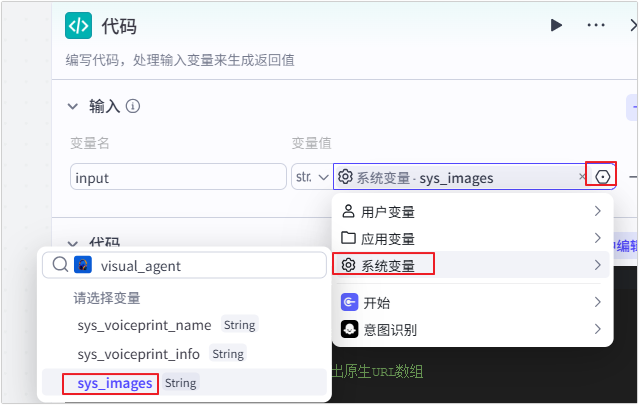 |
| **代码** | 对 `sys_images` 带转义的字符串进行显式解析,去除转义字符,输出标准的图片 URL 字符串数组 `Array`。 | 1. 单击**在IDE中编辑。**
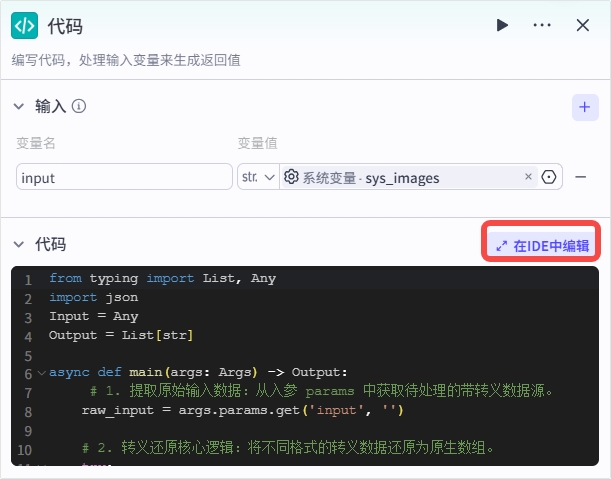
2. 输入以下代码:
```Python
from typing import List, Any
import json
Input = Any
Output = List[str]
async def main(args: Args) -> Output:
# 1. 提取输入:从入参 params 中获取带转义的图片 URL 数据源。
raw_input = args.params.get('input', '')
# 2. 核心逻辑:还原带转义的URL数据为原生字符串数组
try:
# 场景1:输入是整体转义的 JSON 字符串(如 "\"[\"url1\",\"url2\"]\"")。
# 处理:解析为 Python 原生数组(如 "[\"url1\"]" → ["url1"])。
if isinstance(raw_input, str):
native_array = json.loads(raw_input)
# 场景2:输入是数组但元素含转义(如 ["https:\\/\\/xxx.jpeg"])。
# 处理:逐个解析字符串元素,去除内部转义符。
elif isinstance(raw_input, list):
native_array = []
for item in raw_input:
# 仅处理字符串元素(如 https:\\/\\/xxx" → "https://xxx")。
parsed_item = json.loads(f'"{item}"') if isinstance(item, str) else item
native_array.append(parsed_item)
# 场景3:输入为数字/布尔值等其他类型,返回空数组。
else:
native_array = []
# 异常兜底:解析失败/类型错误时,输入为数组则原样返回,否则返回空数组。
except (json.JSONDecodeError, TypeError):
native_array = raw_input if isinstance(raw_input, list) else []
# 3. 类型约束:确保输出为符合定义的原生URL字符串数组。
ret: Output = native_array
return ret
```
|
| **输出** | 在代码节点的输出配置中,将变量类型设置为 Array。 | 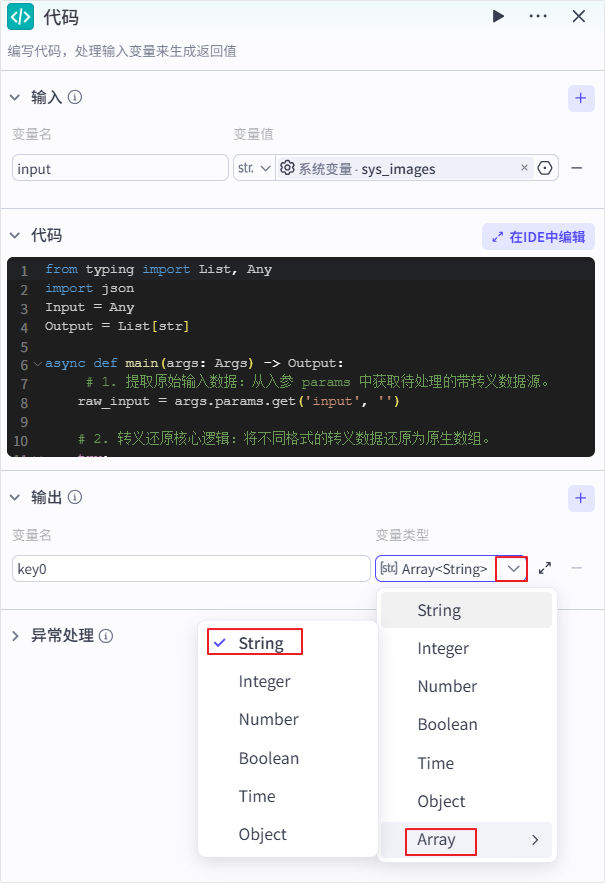 |
2. 连接大模型节点。
修改大模型节点的视觉输入,将其值从引用系统变量 `sys_images` 改为引用上一步骤代码节点的输出。