# 低代码工作流常见问题
## 低代码智能体或应用中的工作流数量有限制吗?
在低代码智能体中无工作流数量限制。在应用中添加工作流时,最多可添加 100 个工作流、100 个对话流。单个低代码工作流最多添加 1000 个节点,且每次运行所有节点共计最多执行 1000 次(含循环次数)。工作流的限制说明,请参考[低代码工作流使用限制](https://docs.coze.cn/api/open/docs/guides/workflow_limits)。
## 如何生成一个 Array 类型的参数?
飞书多维表格 add_records 等节点的必选输入参数中要求参数格式为 Array。对于 Array 类型的输入参数,建议引用前置节点中的输出参数,目前代码等类型的节点支持 Array 类型的输出参数。如果你需要将多个不同类型的参数拼接为一个 Array 类型的参数,可以考虑使用代码节点进行参数拼接。
例如通过代码节点拼接用户提问字段 `input` 和模型回复字段 `output`,并将这两个字段分别写入多维表格的`问题`和`Bot回答`两列中。
工作流示例:
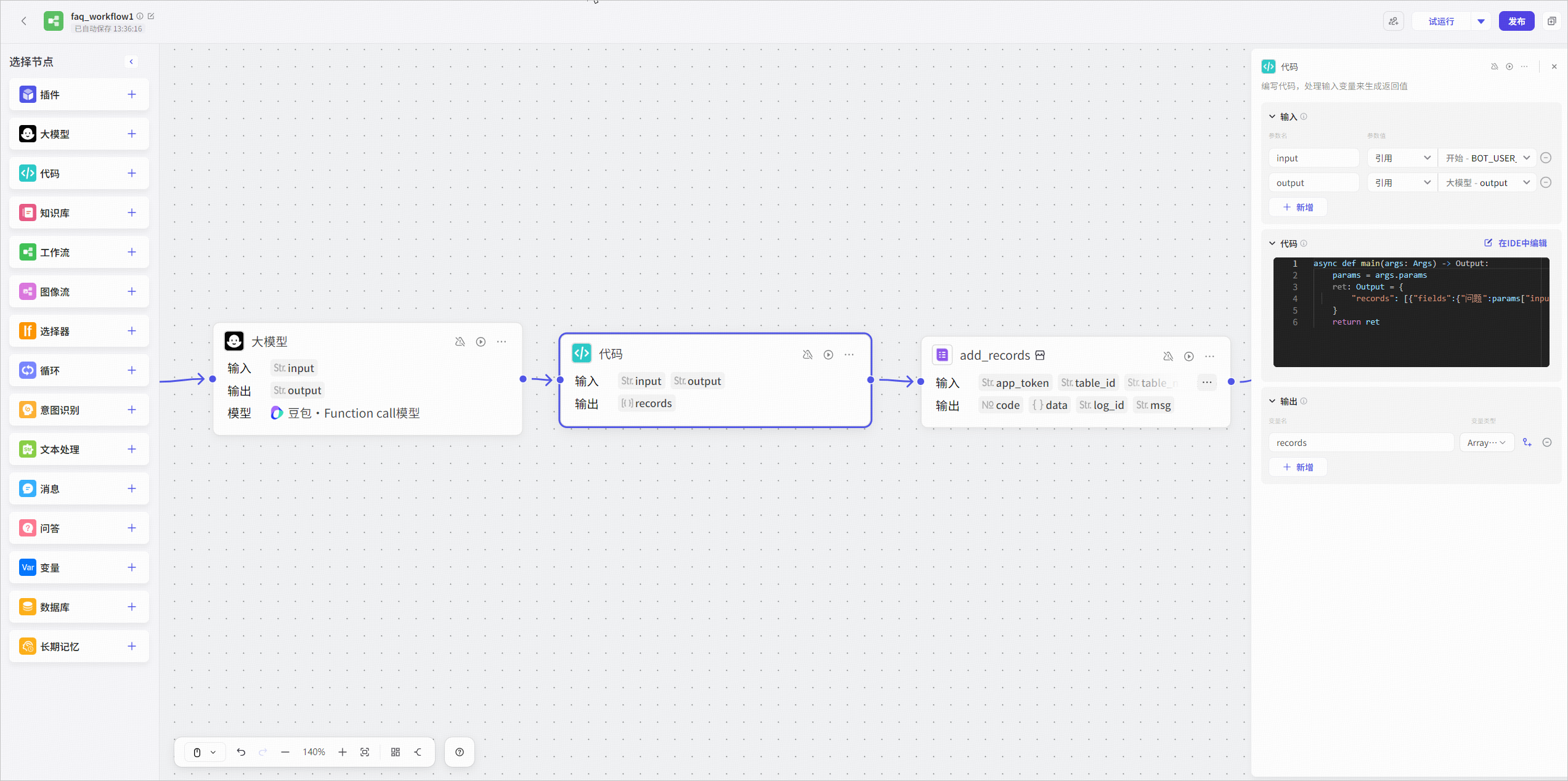
代码示例:
```Python
async def main(args: Args) -> Output:
params = args.params
ret: Output = {
"records": [{"fields":{"问题":params["input"],"Bot回答":params["output"]}}]
}
return ret
```
## Array 类型的输入参数可以指定一个固定值吗?
所有类型的参数均支持指定为一个固定的值,但指定的固定值会被作为 String 类型写入。对于 Array 类型的输入参数,建议引用前置节点中的输出参数,如果一定要指定固定的值,可以在此节点之前增加一个代码节点,将固定值转为 Array 类型,并引用代码节点的输出。
例如:
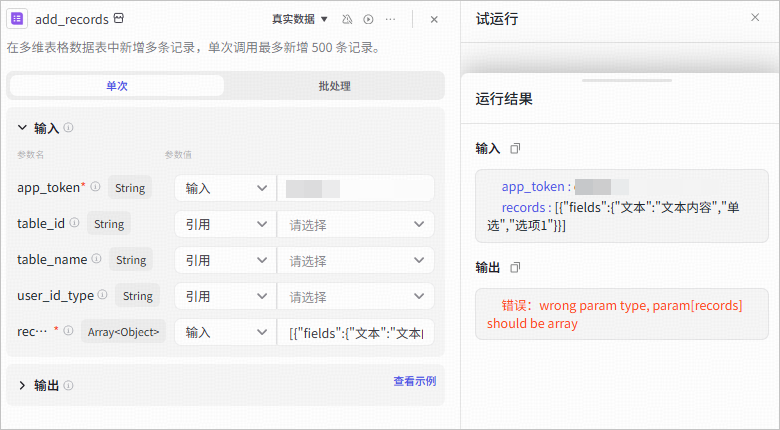
**错误输入**:
直接将 List 格式的 records 参数设置为固定值时,页面报错`错误:wrong param type, param[records] should be array`。
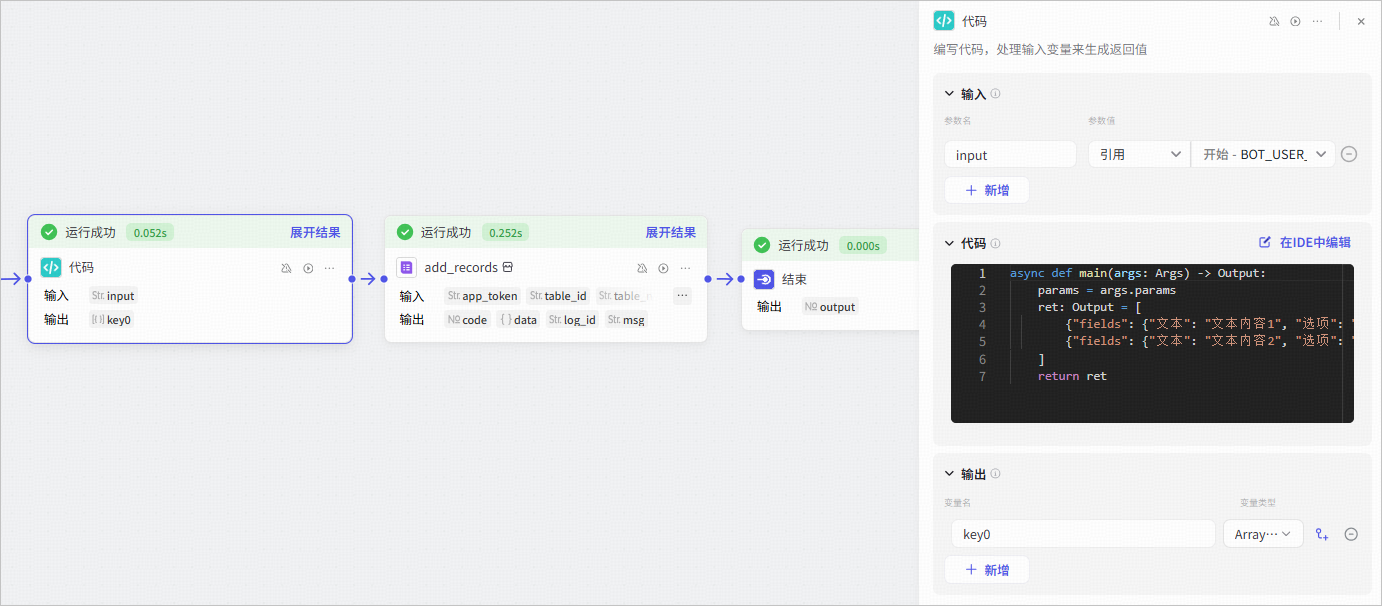
**正确输入**:
增加一个代码节点,用于将固定的值转为 Array 类型的参数,records 引用代码节点的输出参数,工作流执行成功。
## 如何引用数组中的对象
**结束**节点、**输出**节点和**大语言模型 LLM** 节点等节点支持直接引用当前节点导入的参数,且支持联想,当输入`{{`后,能够自动关联所引用的数组/对象数据。
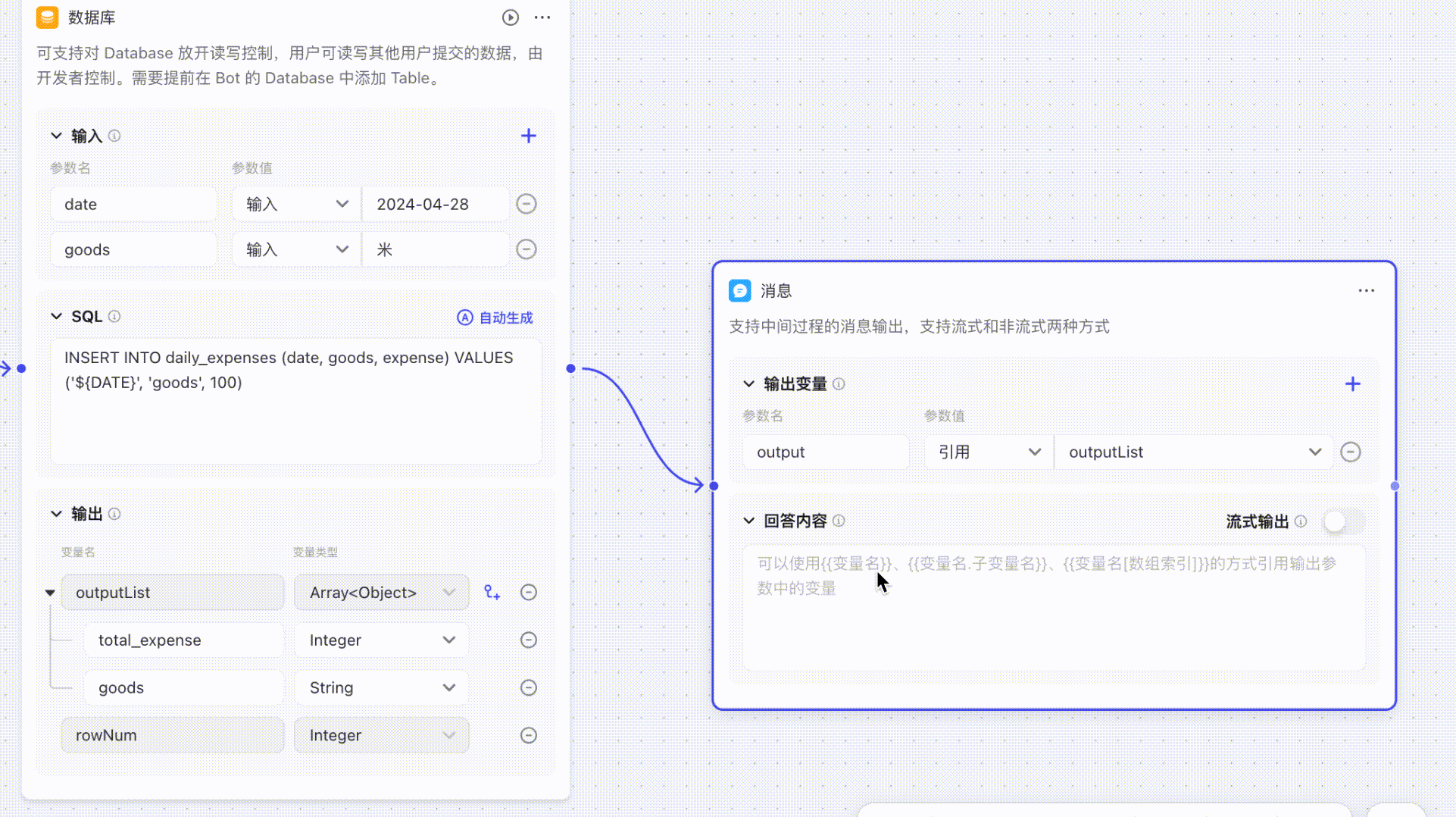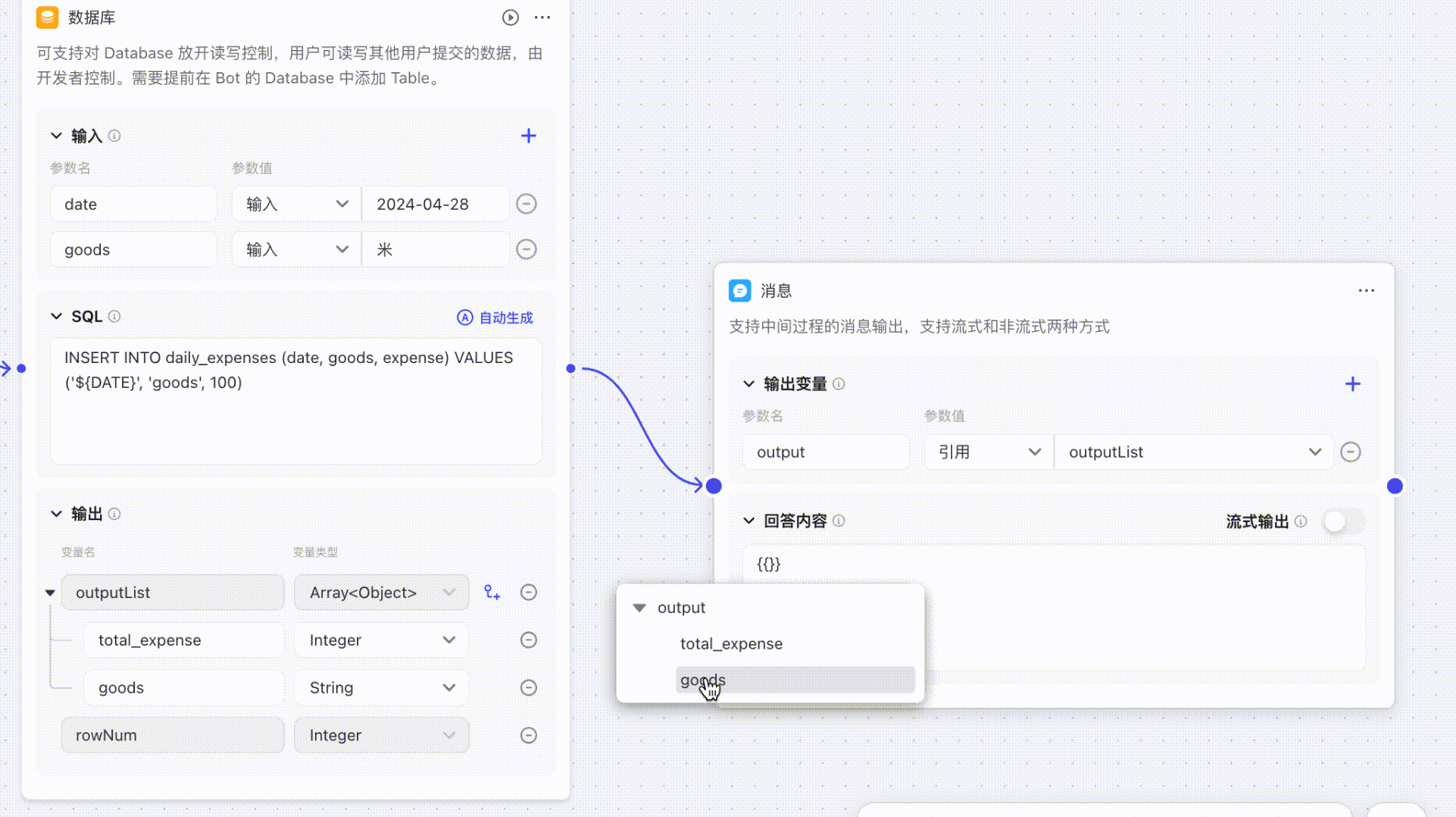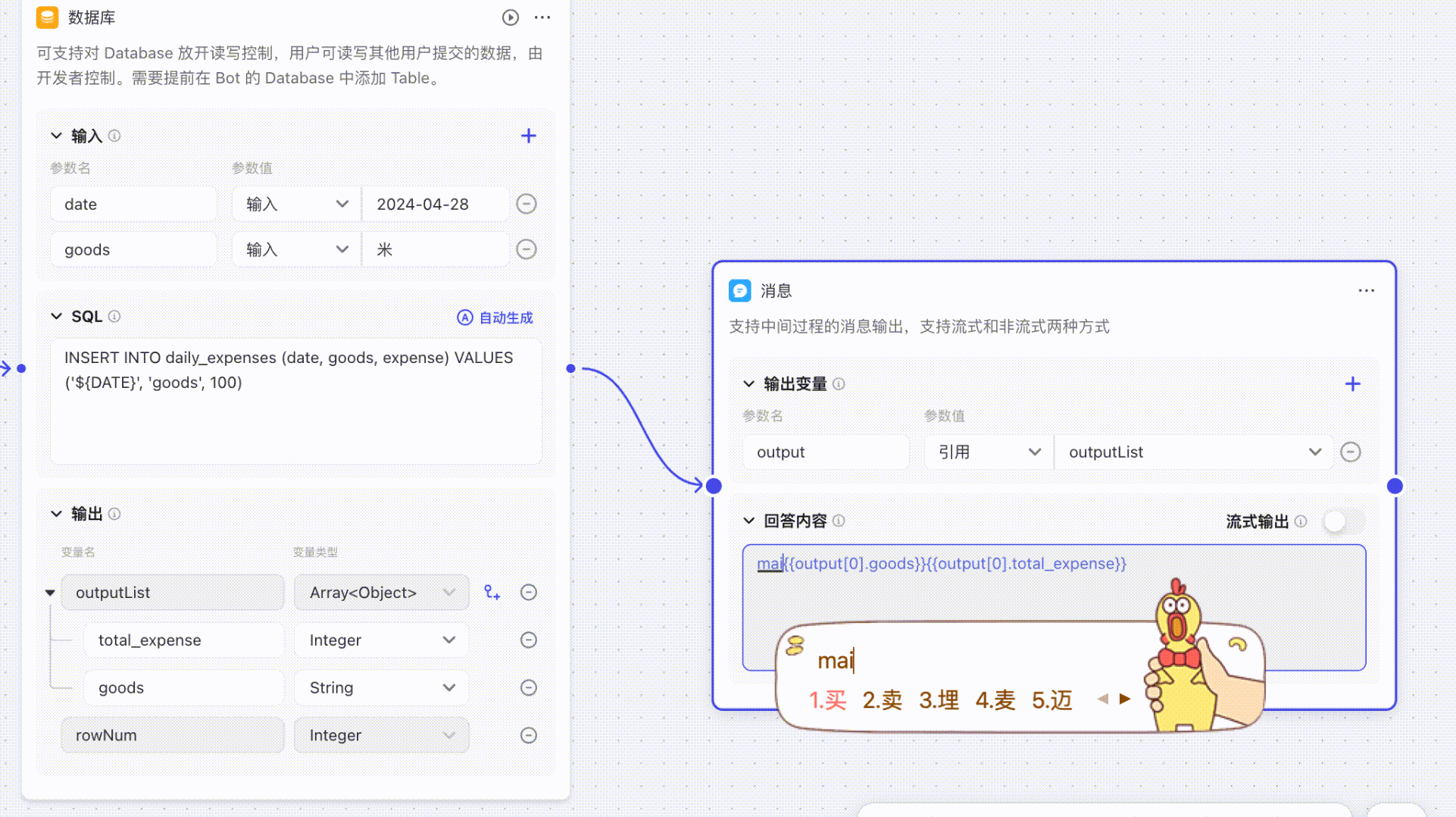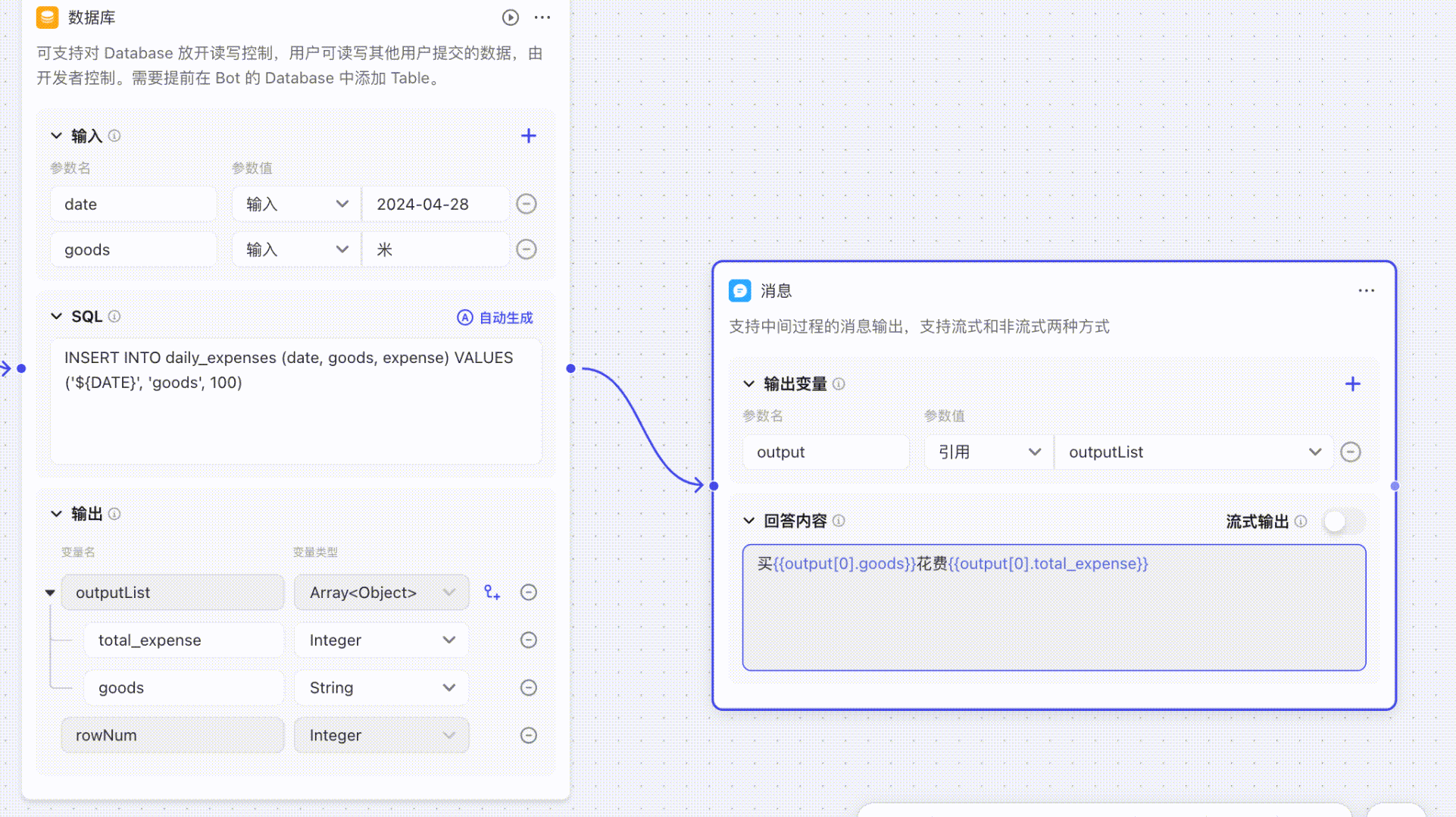
## 低代码智能体没有按照预期调用插件或低代码工作流
如果智能体没有按照预期调用插件或者工作流,你可以尝试:
* 在智能体的**人设与回复逻辑**区域,通过自然语言明确要求智能体在何种场景下调用哪个插件或者工作流。
* 如果是你自己创建的插件或工作流,可以优化插件或工作流的名称和简介,便于智能体准确识别插件或工作流的功能,提高智能体自动使用插件或工作流的概率。
## 低代码工作流中,低代码智能体连续两次回复的时间间隔限制**是多久?**
一次对话中,智能体连续两次回复的时间间隔限制为 10 分钟。
工作流的输出节点、问答节点等节点会在工作流运行期间主动向用户发送消息。工作流运行时,如果智能体连续两次发送消息的时间间隔大于 10 分钟,后端服务会判断工作流运行超时,停止运行工作流并报错。例如节点数量多、工作流逻辑复杂时可能后端处理时间长,导致工作流运行超时。
建议合理编排设置工作流,缩短两次智能体回复的时间间隔,避免后端服务判断超时。例如在后端处理耗时较久的环节适当增加输出节点、为输出节点或结束节点开启流式输出,尽量缩短智能体消息的时间间隔。
## 运行低代码工作流时提示节点中有不合法的内容,怎么解决?
运行工作流时提示节点中有不合法的内容,通常是因为工作流某个节点的配置内容中存在敏感词汇,被拦截导致。你可以通过试运行功能逐个测试工作流中的节点,定位具体是哪个节点触发了不合法内容提示。
## 低代码工作流运行时间超过 10 分钟导致运行超时,怎么解决?
工作流默认为同步运行,整体超时时间为 10 分钟。如果工作流复杂或包含一些运行耗时长的节点,可能会导致工作流整体运行耗时长,智能体判断为工作流运行超时。
在这种场景下,你可以设置工作流为异步运行,整体超时时间为 24 小时。工作流异步运行时会默认返回一条预设的回复内容,用户可以继续与智能体对话,工作流运行完毕后智能体会针对触发工作流的指令做出最终回复。详细信息请参考[步骤四:(可选)设置异步运行](https://docs.coze.cn/api/open/docs/guides/use_workflow#00d7b009)。
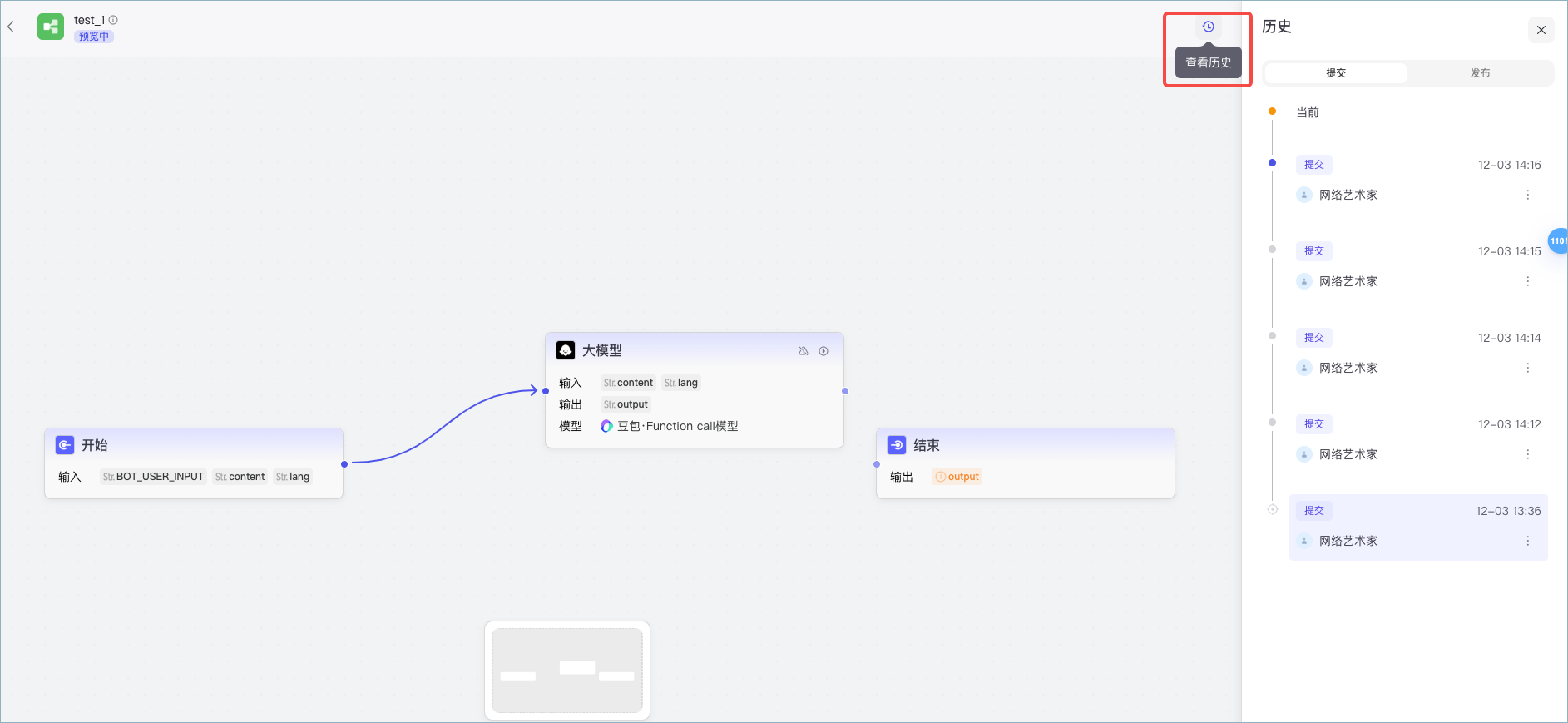
## 如何恢复低代码工作流的历史版本
仅工作空间中开启了**多人协作**的工作流可以查看并恢复历史版本,操作步骤可参考[管理历史版本](https://docs.coze.cn/api/open/docs/guides/collaborate_workflow#579a76e3)。
## 设置参数时显示“(x)暂无数据”
为工作流节点的变量设置参数值时,如果希望引用上游节点的输出参数,但页面显示暂无数据,可能原因如下:
* 此工作流节点未连接任何上游节点。建议从节点左侧添加一条连接线,连接到其他节点后重试。
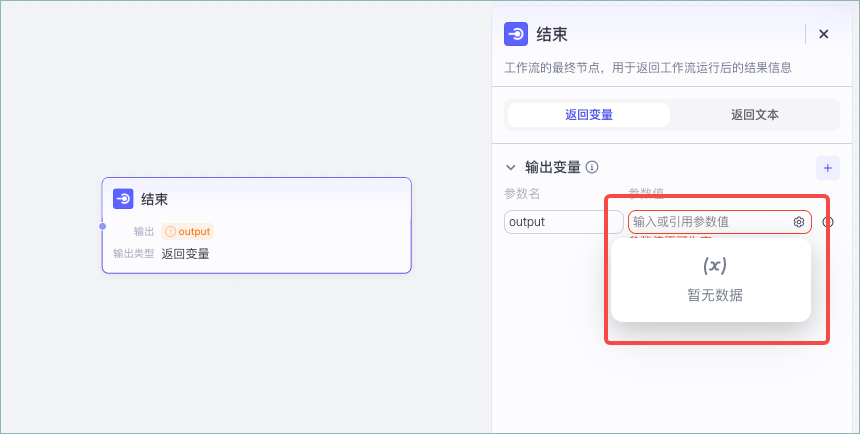
* 此节点上游未定义任何参数。建议在上游节点合理设置参数,或为此节点的参数设置一个固定值。
* 此参数限制数据类型,且上游节点没有符合此数据类型的参数。例如某个插件节点的输入参数固定为 Array,那么它引用的参数必须是同类型的参数,参数值的下拉列表中也仅展示 Array 的参数。
## 低代码**工作流报错“工作流的版本号冲突: xxx” ,应如何处理?**
### 问题现象
工作流运行时报错**“工作流的版本号冲突,冲突工作流 ID: xxx,父工作流 ID: xxxx”** ,其中“xxx”部分为工作流的 ID。

### 原因及方案
#### 版本号冲突
如果某个工作流通过工作流节点嵌套的方式多次引用了另一个工作流,那么必须引用同样的工作流版本。如果子工作流发布了新版本,但是父工作流仅更新了部分节点版本,并未更新每一处引用的版本,会导致父工作流引用的同一子工作流版本不一致,引发此报错。
例如,工作流 A 引用了工作流 C,同时也引用了包含工作流 C 的工作流 B。如果工作流 A 直接引用的工作流 C 版本号升级为 V0.0.2,但工作流 B 引用的工作流 C 仍为旧的版本 V0.0.1,那么执行工作流 A 时页面会报错“工作流的版本号冲突: {工作流C的ID}**,父工作流 ID: {工作流B的ID}, {工作流A的ID}**”。

解决方案如下:
报错中会显示版本冲突的父工作流、子工作流 ID,你可以凭借此 ID 定位到工作流名称,并在父工作流中升级引用的此子工作流版本,保证每一处均引用最新版本。具体操作步骤如下:
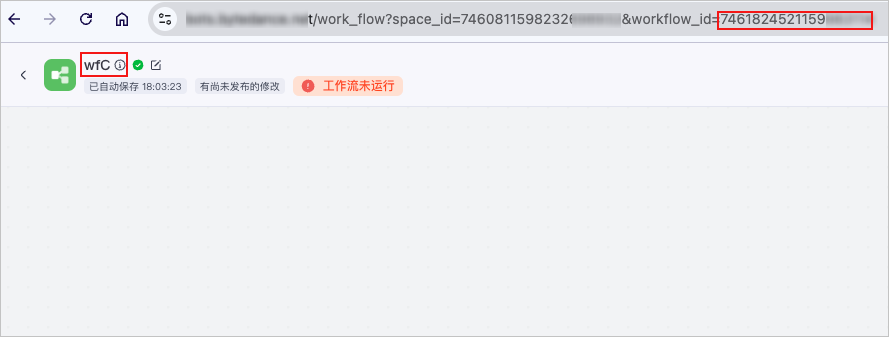
1. **确定版本冲突的子工作流名称**。
在资源库中打开任意工作流,将 URL 中 `workflow_id=` 之后的字符串替换为报错信息中获取的子工作流 ID“xxx”,重新访问此页面后可在页面左上角查看工作流名称。例如以下工作流 ID 对应的工作流名称为 `wfC`。
2. **找到对应的父工作流节点**。
报错信息中包含父工作流 ID,你可以通过同样的方式定位到嵌套了这个子工作流的所有父工作流。
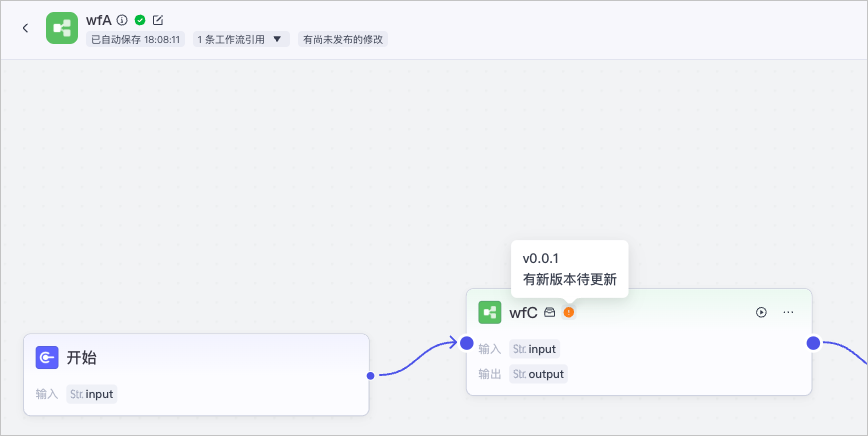
打开运行报错的父工作流,确认父工作流的每一个工作流节点是否引用了步骤1中找到的子工作流。注意工作流节点可能存在多层嵌套关系,例如父工作流 A 嵌套工作流 B,工作流 B 中又嵌套了工作流 C,你需要找到工作流 A 中引用工作流 C 的每一个节点。这些节点引用的工作流 C 版本不是完全一致的。
在工作流节点中,如果节点名称之后存在红色标签提示,表示这个子工作流已发布了最新版本,但当前引用的是历史版本。鼠标指向这个标签即可查看引用的子工作流版本号。
3. **为每个工作流节点升级子工作流的版本**。
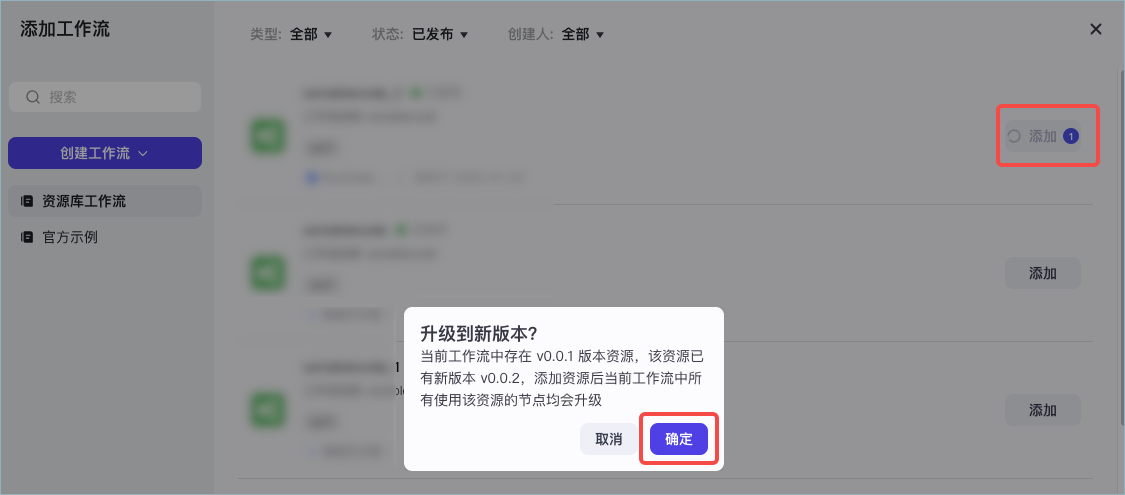
在工作流 A 中,为每一个引用子工作流 C 的节点升级工作流版本,确保这些节点引用的工作流 C 版本一致。目前仅支持升级到最新版本。升级子工作流版本的方式可参考[引用低代码工作流版本](https://docs.coze.cn/api/open/docs/guides/workflow_version#c6aaf871)。
全部升级后,可以试运行这个工作流,如果试运行通过,表示此版本冲突的问题已解决。

#### 历史数据问题
对于工作流版本管理功能上线前已经存在的工作流节点,节点中可能不显示工作流版本,表示此节点始终引用最新版本工作流。如果工作流中同时存在带版本号和不带版本号的工作流节点,即使这些节点引用的同一版本,也会导致此报错。
对于不显示版本号的工作流节点,建议在当前工作流中新增一个相同的工作流节点,新增时根据页面提示更新工作流版本,更新后原工作流节点会自动显示版本号信息。然后删除这个新增节点即可。
## 如何规避低代码工作流存储对话记录到飞书多维表格时的飞书授权提示?
不支持规避飞书授权环节,因为飞书平台要求用户必须完成授权验证才能进行数据写入操作。详情请参考飞书开放平台权限验证机制。
## 发布低代码工作流报错“插件调用报错”,如何处理
发布工作流时,如果页面报错“插件调用报错”,通常原因是发布时指定了一个已存在的版本号,建议更换版本号后重新发布。
## 如何从数组类型的输出参数中提取字符串?
部分插件的输出结果为 Array 类型的 URL,当后续节点需要 String 类型的 URL 作为输入时,你需要先提取数组中的 URL。这可通过文本处理节点或代码节点实现。
* 文本处理节点:配置简单,但不支持动态配置。当数组中只有一个 URL 时,可通过文本处理节点直接提取数组中的第一个元素。
* 代码节点:配置较复杂,但支持动态配置。当数组中包含多个 URL 时,如果你需要提取所有的元素或仅提取最后一个元素,可使用代码节点进行提取。
**文本处理节点**
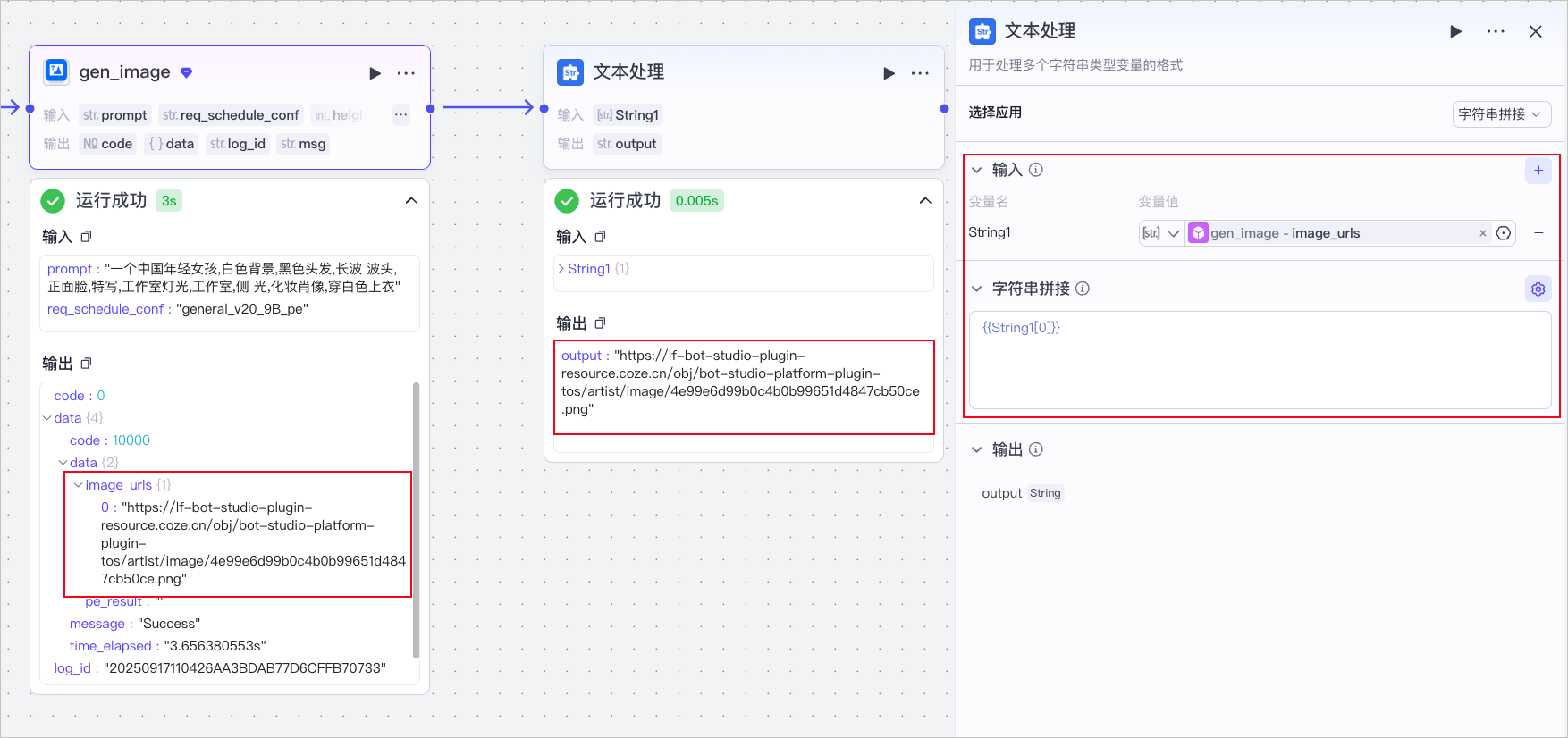
例如 **Doubao-图像生成插件** gen_image 工具中的 `data.data.image_urls` 参数为数组类型,但仅包含一个元素,因此通过**文本处理节点**提取第一个元素即可。
1. 在文本处理节点,选择**字符串拼接**应用。
2. 设置变量 `String 1` 引用 gen_image 节点中的输出参数 `image_urls`。
3. 在**字符串拼接**区域,输入` {{String1[0]}}`,提取数组中的第一个元素。
**代码节点**
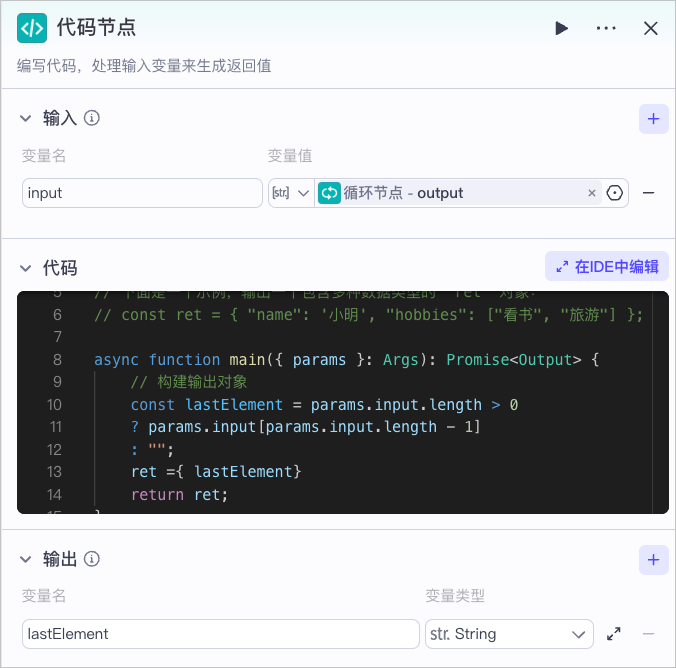
例如使用循环节点时,输出结果为 Array 类型,当后续节点需要使用数组中的最后一个元素时,你可以通过代码节点进行提取。
在代码节点中,完成如下配置。
* 新增输入参数 `input`,设置为 Array 类型,引用循环节点的输出结果 `output`。
* 配置代码,代码示例如下:
```JavaScript
async function main({ params }: Args): Promise {
// 构建输出对象
const lastElement = params.input.length > 0
? params.input[params.input.length - 1]
: "";
ret ={ lastElement}
return ret;
}
```
* 新增输出参数 `lastElement`,设置为 string 类型。
## 如何查看输入和输出消耗的 tokens 以及每个节点消耗的 tokens?
你可以通过如下三种方式查看已消耗的 tokens:
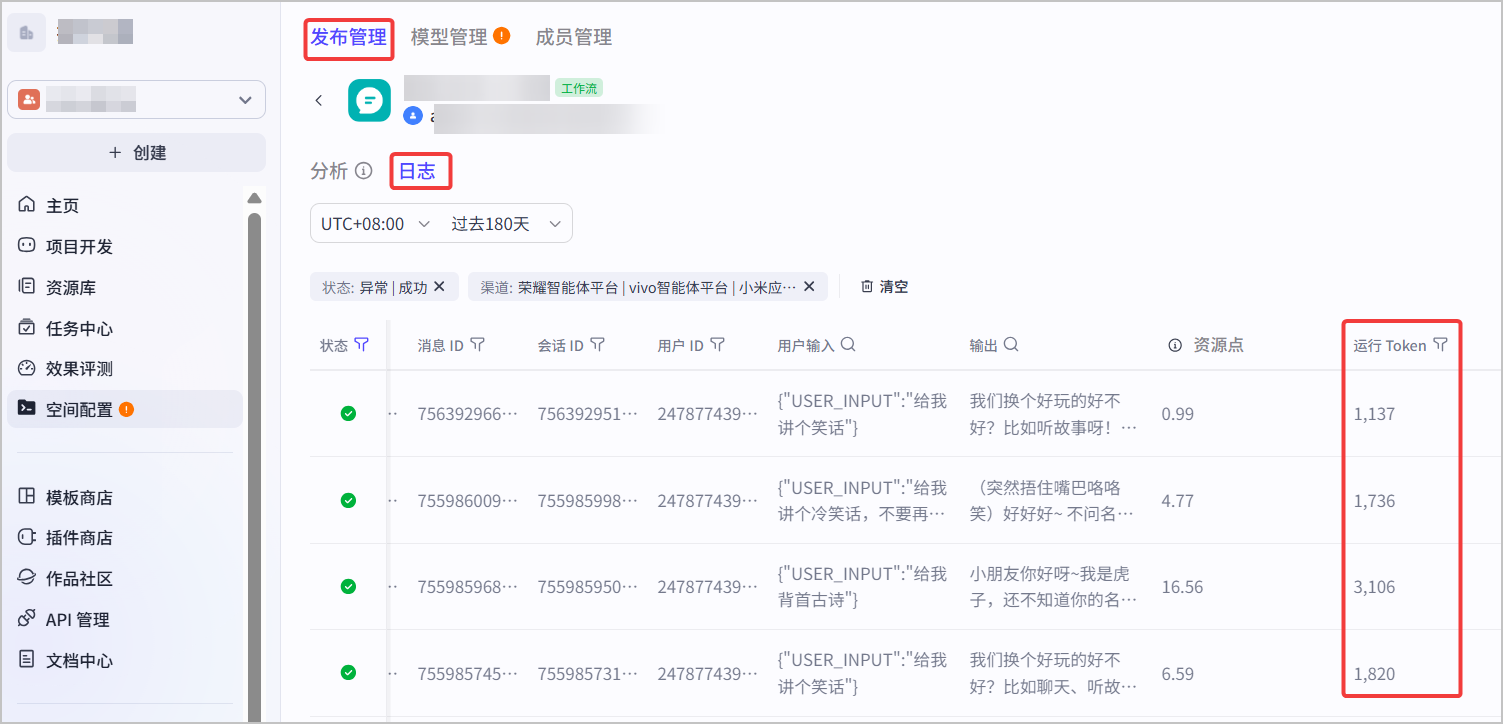
* 在**消息日志**中查看线上运行记录及其资源消耗
在**空间配置** > **发布管理** > **消息日志**中,你可以查看智能体或工作流每次调用消耗的 tokens。
如果要查看每个节点消耗的 tokens 数量,你可以单击某条消息日志,在调用树中单击对应的节点,在输出的 usage 参数中查看该节点本轮对话消耗的 tokens。具体请参见[查看消息日志](https://docs.coze.cn/api/open/docs/guides/queries#b3343fa8)。
消息日志中的 tokens为估算值,仅供参考,具体消耗以[火山引擎账单](https://console.volcengine.com/finance/bill/detail)实际为准。
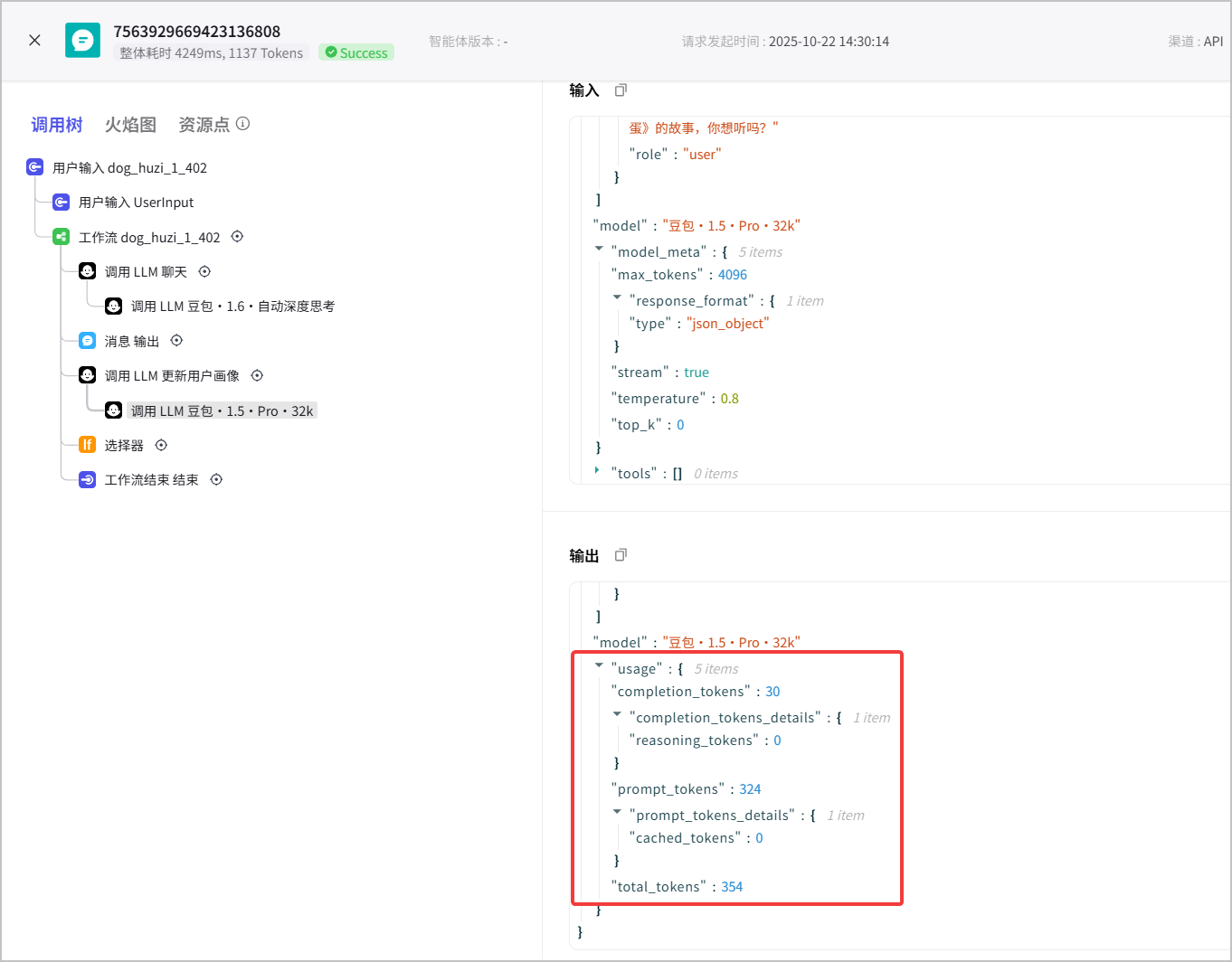
* 调用[发起对话](https://docs.coze.cn/api/open/docs/developer_guides/chat_v3)或[执行工作流](https://docs.coze.cn/api/open/docs/developer_guides/workflow_run) API 时,通过返回参数中的 `usage` 字段,你可以查看本次 API 调用消耗的 Token 数量。
此处大模型返回的消耗 Token 仅供参考,以[火山引擎账单](https://console.volcengine.com/finance/bill/detail)实际为准。
* 试运行时在调试区查看
你可以在如下页面查看单次智能体对话、工作流试运行所消耗的积分。
| **查看入口** | **说明** | **示例** |
| --- | --- | --- |
| 智能体调试区