# 知识库检索节点
知识库是智能体的私有知识合集,低代码工作流中的知识库检索节点可以基于用户输入查询指定的知识库,召回最匹配的信息,并将匹配结果以列表形式返回。
## 使用限制
使用火山知识库时,节点的请求频率限制遵循火山知识库自身的 QPS 配额限制。更多信息,请参考[接口限流说明](https://www.volcengine.com/docs/84313/1339026#%E6%8E%A5%E5%8F%A3%E9%99%90%E6%B5%81%E8%AF%B4%E6%98%8E-2)。
* 写入文本到火山知识库文档时,将调用 [/api/knowledge/point/add](https://www.volcengine.com/docs/84313/1386607) 接口,该接口的 QPS 为 10。
* 上传新文档到火山知识库时,将调用 [/api/knowledge/doc/add](https://www.volcengine.com/docs/84313/1254624) 接口,该接口的 QPS 为 300。
* 检索火山知识库中的文档时,将调用 [/api/knowledge/service/chat](https://www.volcengine.com/docs/84313/1544072) 接口,该接口与部分火山知识库接口共享 QPS,其值为 50。
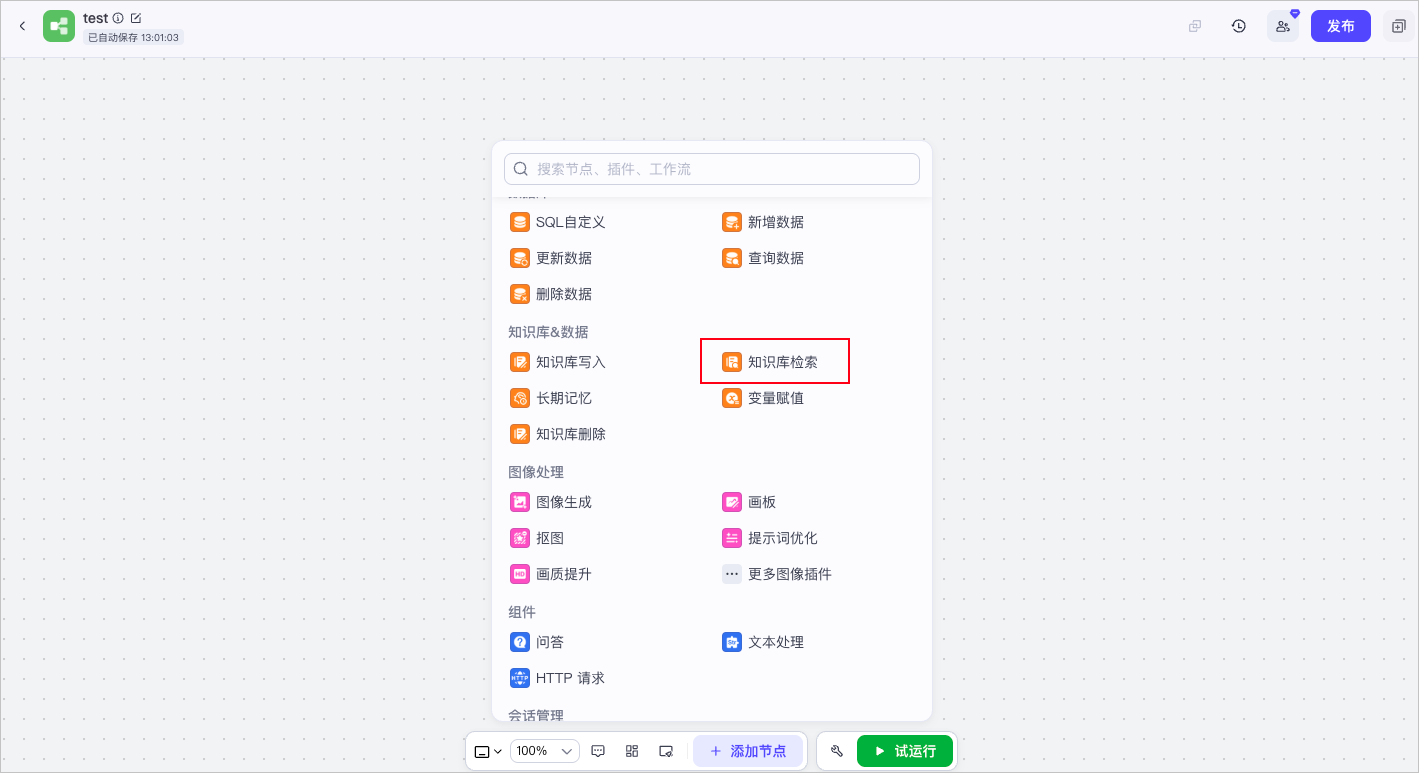
## 添加节点
在工作流画布中,单击 **+ 添加节点**,在**知识库&数据**区域选择**知识库检索**节点,即可将节点添加到画布中。
## 配置节点
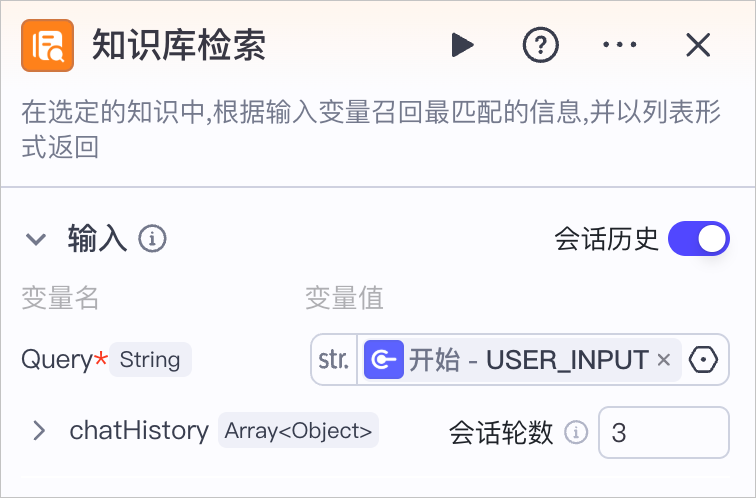
### 输入
知识库节点的输入参数固定为 Query,表示用户希望在知识库中检索的关键信息,需要引用上游节点的输出参数。输入参数格式为 String,可以引用任何格式的数据。
在对话流中,知识库检索节点支持开启智能体的会话历史功能。开启后,该节点检索知识库时会参考会话上下文信息。同时,支持设置带入模型上下文的会话轮数,会话轮数越多,多轮对话的相关性越高,但消耗的 Token 也越多。
### 知识库
在**知识库**区域,选择待检索的知识库。支持选择已创建的火山知识库或扣子知识库,只能设置同类型的知识库,暂不支持同时选择两种知识库。
#### 火山知识库
扣子编程支持关联已有的火山知识库,其中知识库的创建、标签的创建、召回策略的配置均在火山知识库侧完成。检索火山知识库时,如果配置了标签,那么火山知识库侧会先根据标签筛选文档,然后根据召回策略检索匹配知识库内容,扣子编程通过**服务调用**直接获取已召回的内容,并返回给用户查看。
在知识库检索节点中配置火山知识库之前,应确认已在火山知识库控制台创建知识库、上传文件、配置召回策略并发布为知识检索类型的服务调用,并在扣子编程中关联了火山知识库。操作步骤可参考[关联火山知识库](https://docs.coze.cn/api/open/docs/guides/kir27ori)。
例如下图中,`coze_doc` 为火山知识库名称,`test` 为知识服务名称。
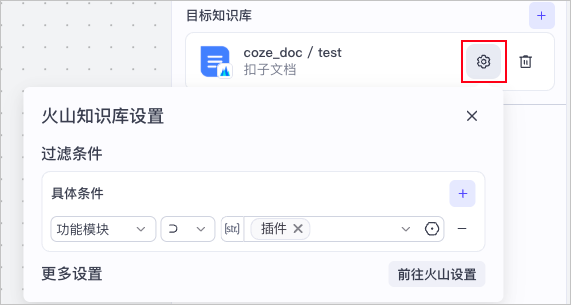
选择火山知识库后,你可以单击其对应的**设置**图标,设置对应的过滤条件和召回配置。
* 标签过滤条件:如果你为火山知识库中的文档添加了标签,那么你可以通过标签设置过滤条件,以实现知识库检索时,将先在标签范围内检索文档,然后结合召回策略返回结果。过滤条件格式为`标签名 操作符 标签值`。
* 标签名:仅在创建知识库时创建了标签,此处才能选择对应的标签名。
* 操作符:不同的数据类型支持的操作符不同,以实际页面为准。
* 标签值:支持设置为固定值或引用变量。
例如设置过滤条件为 `功能模块 包含 插件`,那么系统将会筛选出本知识库中所有带有**功能模块**标签且标签值包含**插件**的文档。
仅火山知识库旗舰版支持标签功能。
* 召回策略:知识库的召回配置在很大程度上会影响召回结果的准确性、相关性。你可以单击**前往火山设置**,在火山知识库控制台查看已配置的召回策略,包括返回文本片数量、重排模型、Dense Weight 等。如需修改召回配置,必须将该配置发布为新的知识服务,并在此处选择新的知识服务。
#### 扣子知识库
选择**扣子知识库**,并配置召回策略。知识库的召回配置在很大程度上会影响召回结果的准确性、相关性。
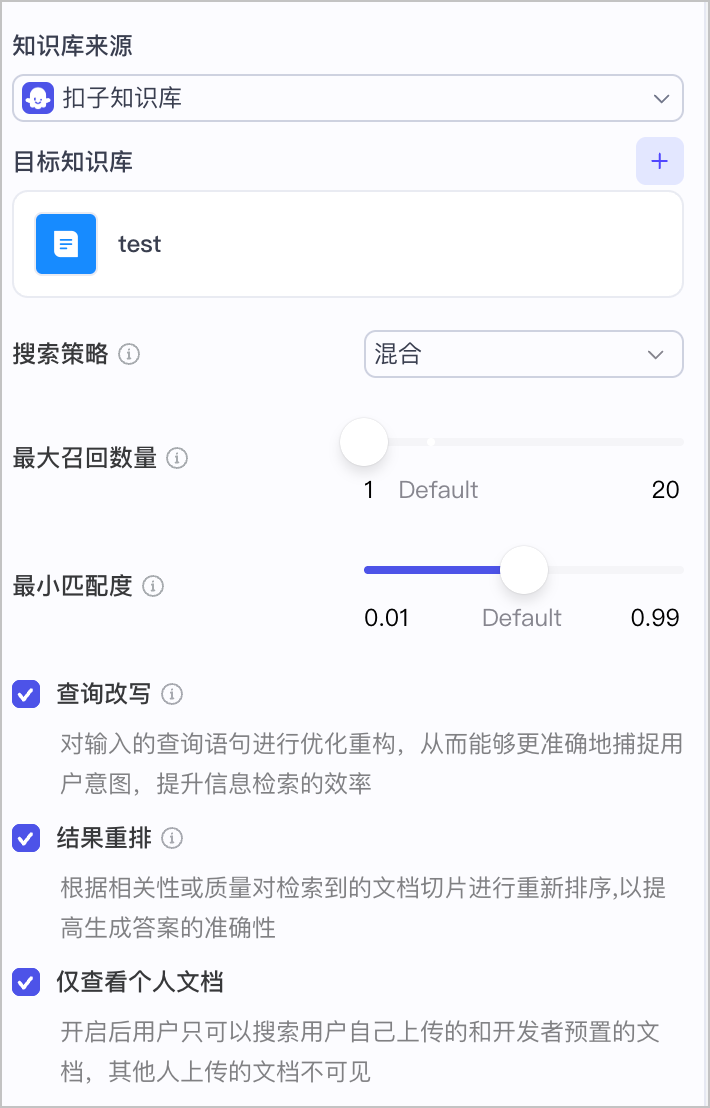
### 扣子知识库召回策略
#### 搜索策略
从知识库中获取知识的检索方式,不同的检索策略可以更有效地找到正确的信息,提高其生成的答案的准确性和可用性。支持的检索策略包括:
* **混合**:结合全文检索和语义检索的优势,并对结果进行综合排序召回相关的内容片段。
* **语义**:像人类一样去理解词与词、句与句之间的关系。推荐在需要理解语义关联度和跨语言查询的场景使用。例如下面两组句子,第一组的语义关系更强。
```Plain Text
"狼追小羊"和"豺狼追山羊"
"狼追小羊"和"我爱吃炸猪排"
```
* **全文**:基于关键词进行全文检索。推荐当查询内容包含以下场景时使用:
* 特定名称或专有名词、术语等,例如比尔盖茨、 特斯拉 Model Y。
* 缩写词,例如 SFT。
* ID,例如 12s1w1s2 系列。
#### 表格 SQL 查询
添加了表格知识库之后,默认开启表格 SQL 查询。开启后,查询表格知识库时,系统会自动将用户输入的自然语言转为 SQL 语句,根据 SQL 对表格知识库进行查询计算,SQL 执行结果与 RAG 召回的切片会一同传递给模型。
* 暂不支持跨表查询操作(JOIN)。
* 知识库检索节点中添加了表格知识库时,才能使用表格 SQL 查询功能。
#### 最大召回数量
从知识库中返回的最大段落数量。数值越大,返回的条目越多。默认召回 5 条检索结果。
#### 最小匹配度
匹配度指的是系统检索到的上下文与被视为 ground-truth 的标注答案对齐的程度。设置最小匹配度参数后,系统会根据设置的匹配度选取段落,低于指定匹配度的内容不会被召回。默认的最小匹配度为 0.5。
#### 查询改写
在多轮对话中,用户的 Query 和对话的上下文息息相关,仅凭借用户最新一条提问可能无法正确识别用户的真实检索意图。查询改写是指根据对话历史对用户输入的 Query 进行优化或重构,从而更准确地捕捉真实的用户意图,提升信息检索的效率。知识库检索节点默认开启查询改写。
例如用户对话的上下文为:
* 问题1:知识库检索节点可以用来做什么?
* 回复1:知识库检索节点可以基于用户输入查询指定的知识库,召回最匹配的信息,并将匹配结果以列表形式返回。
* 问题2:怎么用?
对于问题2,不参考上下文的情况下无法判断用户的真实意图。开启查询改写后,问题2会被改写为“知识库检索节点怎么用?”
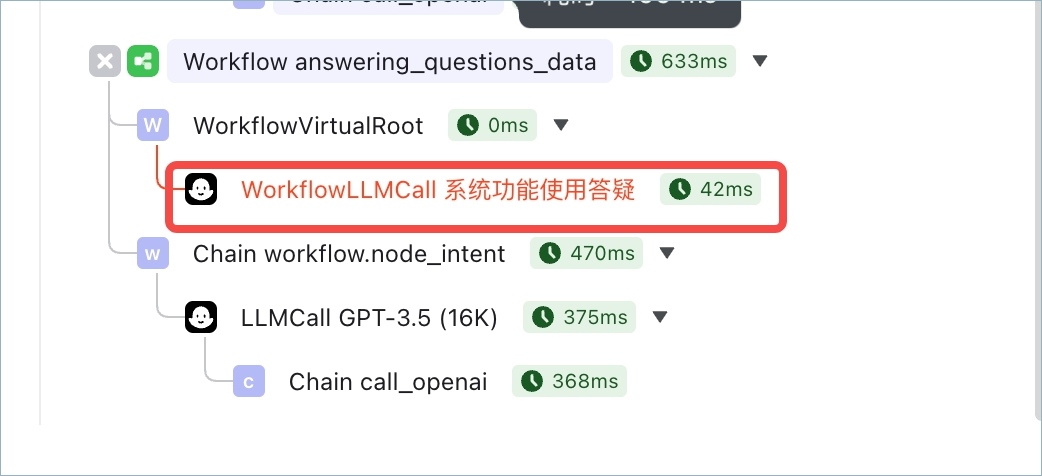
开启查询改写后,知识库节点的处理流程会加一轮模型处理,由大模型来改写用户输入。所以查看消息链路时,可能会看到一个名为 WorkflowLLMCall 的处理环节。
#### 结果重排
结果重排是指根据相关性或质量对检索到的文档切片进行重新排序,以提高生成答案的准确性和相关性,适用于追求回答高精度和高相关性的场景,例如智能客服、专业技术答疑等场景。未开启结果重排时,节点输出的是向量检索的结果,根据匹配度从大到小排序;开启结果重排后,系统会将 Embedding 的召回结果交由 Rerank 模型进行质量和相关性判断,对结果重新排序,将与输入问题最相关的文档排在前面。
假设用户查询“如何制作意大利面?” ,首先会从知识库中检索得到以下几个文档片段,其中先按照ABCD先后顺序排列:
* 切片 A:介绍意大利面的历史。
* 切片 B:讨论了不同种类的意大利面和它们的搭配。
* 切片 C:详细描述了制作意大利面的步骤,包括所需材料和烹饪技巧。
* 切片 D:提供了一些意大利面食谱。
在结果重排的过程中,知识库检索节点会分析用户的真实意图,对切片重新排序,使得最相关的内容排在前面。最终的排序可能变为:
* 切片 C:详细描述了制作意大利面的步骤,包括所需材料和烹饪技巧。
* 切片 D:提供了一些意大利面食谱。
* 切片 B:讨论了不同种类的意大利面和它们的搭配。
* 切片 A:介绍意大利面的历史。
#### 仅查看个人文档
指定查询范围是否仅限于用户的个人文档。默认为关闭状态。
* 开启:在知识库检索节点添加的全部知识库中,用户只能搜索自己通过知识库写入节点写入的文档,不能在开发者和其他人上传的文档中检索内容。
* 关闭:检索范围为知识库节点中添加的全部知识库。
### 输出
输出参数固定为一个名为 outputList 的数组,其中包含多条召回结果,默认根据匹配度和相关性由高到低排序。outputList 数组中包括如下输出参数:
* output:召回结果,数据类型为 String。
* documentId:知识库文档的 ID,数据类型为 String。
## 常见问题
### 知识库检索节点和大模型节点添加知识库有什么区别?
前者是人工指定输入的检索内容,百分百调用。
后者是大模型根据 Query 决定是否调用知识库、以及使用什么内容去检索知识库。