# 集成 WebSocket 实时语音 Web SDK
WebSocket 实时语音 Web SDK (简称 WsChat SDK) 基于双向流式语音对话 WebSocket OpenAPI 封装 ,为开发者提供开箱即用的语音交互解决方案,详细的接口信息请参见[双向流式语音对话](https://docs.coze.cn/api/open/docs/developer_guides/streaming_chat_api)。
## 体验 Demo
扣子提供[实时语音 Demo](https://www.coze.cn/open-platform/realtime/websocket) 和 TypeScript 格式的 [实时语音 WebSocket 示例源码](https://github.com/coze-dev/coze-js/tree/main/examples/realtime-websocket),帮助你快速体验实时语音的功能,并根据示例源码快速实现实时语音。
### Demo 功能简介
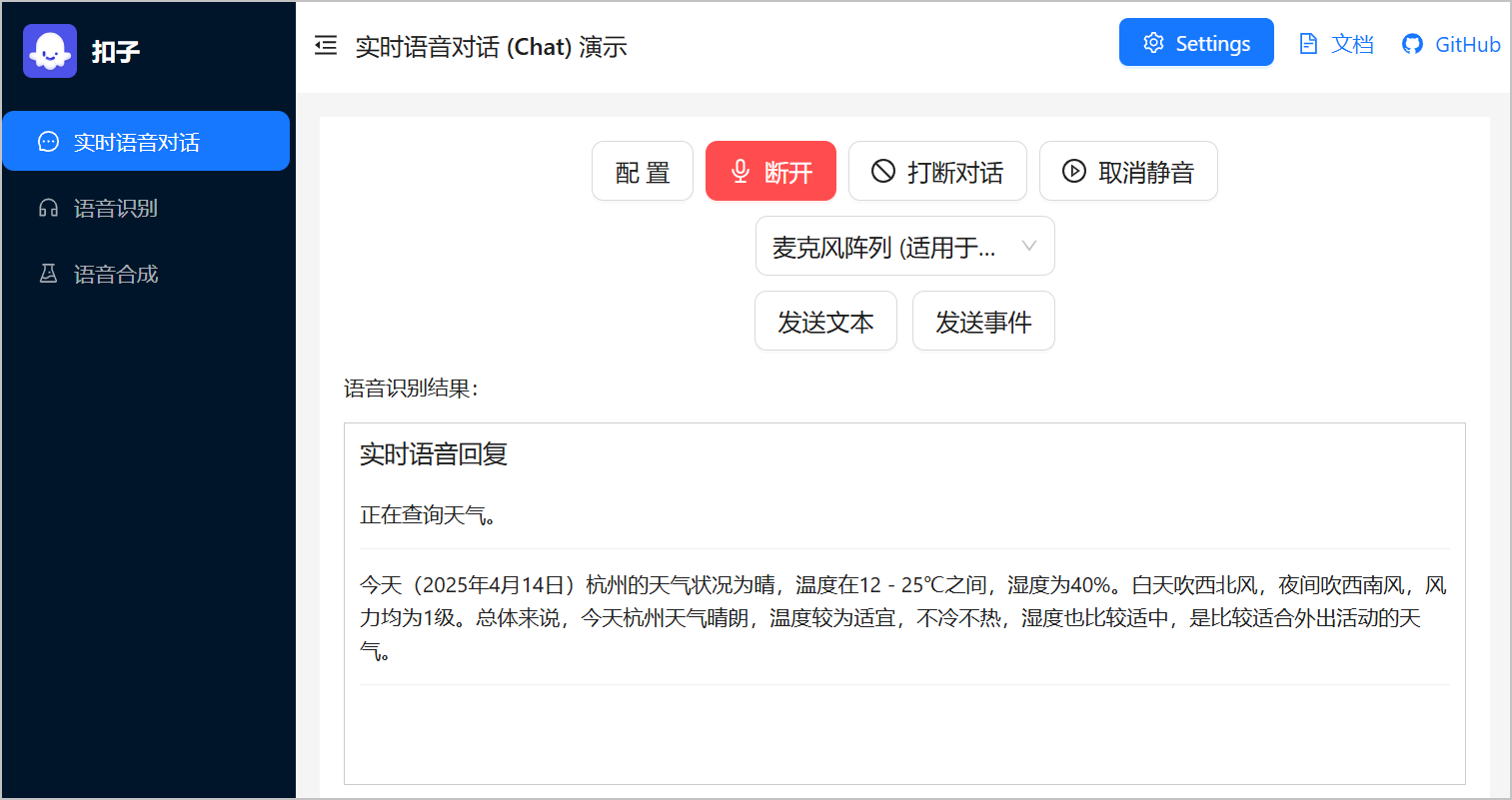
Demo 的主要功能包括:
* 实时语音识别:将用户语音即时转换为文本。
* 配置管理:支持设置降噪模式、音频配置。
* 设备管理:支持设置不同的音频输入设备。
* 交互控制:支持打断对话、静音、发送文本、发送事件等。
* 会话管理:支持建立和断开语音连接、设置静音等。
### 使用 Demo
1. 配置参数。
单击右上角的 **Settings**,配置个人访问令牌和智能体 ID 等参数,具体如下表所示。
| **配置** | **说明** |
| --- | --- |
| Base WS URL | 保持默认值 `wss://ws.coze.cn`。 |
| 个人访问令牌 | 扣子 API & SDK 通过访问令牌进行 API & SDK 请求的鉴权。
个人访问令牌的获取方式可参考[添加个人访问令牌](https://docs.coze.cn/api/open/docs/developer_guides/pat)。
* 应为令牌授予 chat、createVoice 和 listVoice 的权限。
* 令牌授予的访问工作空间中包含了待与其通话的智能体,否则会提示鉴权失败。
|
| 智能体 ID | 配置希望与其实时语音聊天的智能体 ID。
进入智能体的开发页面,开发页面 URL 中 `bot` 参数后的数字就是智能体ID。例如`https://www.coze.cn/space/341****/bot/73428668*****`,智能体ID 为`73428668*****`。
* 确保个人访问令牌开通了此智能体所在空间的权限。
* 确保该智能体已发布为 API 服务。
|
| 音色 ID | 设置智能体使用的音色。扣子提供一系列系统音色,你可以在[系统音色列表](https://docs.coze.cn/api/open/docs/dev_how_to_guides/sys_voice)查看音色 ID。 |
| 工作流 ID | 如果你需要自定义传参,你可以在对话流的开始节点设置自定义参数,然后在本参数中指定相应的对话流 ID。
获取对话流 ID 的方法:通过进入 Workflow 编排页面,在页面 URL 中,`workflow` 参数后的数字就是对话流 ID。例如 `https://www.coze.com/work_flow?space_id=42463***&workflow_id=73505836754923***`,对话流 ID 为 `73505836754923***`。 |
2. 单击**开始对话**,向指定智能体发起实时语音通话。
实时语音通话需要获取设备的麦克风权限,如果页面提示 `[DEVICE_ACCESS_ERROR] Failed to get audio devices`,表示浏览器禁用了麦克风设备。
## 实现流程
### 步骤一: 安装依赖
运行以下命令安装 WsChat SDK 及其依赖项。
```Shell
npm install @coze/api
```
### 步骤二:检查设备权限
在使用语音功能前,先检查并获取麦克风访问权限。调用`WsToolsUtils.checkDevicePermission() `方法,检查浏览器是否已授予麦克风权限。
在 HTTPS 或 localhost 中执行该方法。首次调用时,浏览器会向用户显示权限请求对话框,如果用户拒绝麦克风权限,在应用中提供明确指引,告知用户如何在浏览器设置中启用权限。在 iOS Safari 浏览器中,必须由用户交互操作(如点击按钮)触发权限请求。
```TypeScript
import { WsToolsUtils } from "@coze/api/ws-tools";
const result = await WsToolsUtils.checkDevicePermission();
if (!result.audio) {
throw new Error("需要麦克风访问权限");
}
```
### 步骤三:初始化客户端
调用 `new WsChatClient` 方法创建 WsChatClient 实例,配置 token 和 botId。
```JavaScript
import { WsChatClient } from "@coze/api/ws-tools";
const client = new WsChatClient({
token: 'pat_Qm47PKJR5dvMOP53v6DyzwCbTtvEZHQc2TVINEveg9v1T3iSYlTdScJ8***',
botId: 'your bot id',
allowPersonalAccessTokenInBrowser: true, // 可选:允许在浏览器中使用个人访问令牌
});
```
参数说明:
* **token**:访问密钥,用于身份认证与鉴权。体验或调试场景可以生成短期的个人访问令牌(PAT),以快速完成 WsChat SDK 的整体流程。个人访问令牌的获取方法请参见[添加个人访问令牌](https://docs.coze.cn/api/open/docs/developer_guides/pat)。在线上环境中,应使用服务访问令牌(SAT)或 OAuth 鉴权方案,详细说明请参见[鉴权方式概述](https://docs.coze.cn/api/open/docs/developer_guides/authentication)。
扣子 SDK 封装了多种鉴权方式,能够有效简化鉴权流程,你可以参考[鉴权示例代码](https://github.com/coze-dev/coze-py/tree/main/examples)实现不同方式的 OAuth 认证,以获取和管理访问扣子 API 所需的令牌
* **botId**:配置希望与其实时语音聊天的智能体 ID。进入智能体的开发页面,开发页面 URL 中 `bot` 参数后的数字就是智能体ID。例如`https://www.coze.cn/space/341****/bot/73428668*****`,智能体ID 为`73428668*****`。
### 步骤四:监听事件
在初始化客户端后,通过 `client.on` 方法注册各种事件监听器。详细的事件说明请参见[双向流式对话上行事件](https://docs.coze.cn/api/open/docs/developer_guides/streaming_chat_event)。
```JavaScript
import { WsChatEventNames } from "@coze/api/ws-tools";
// 监听所有事件
client.on(WsChatEventNames.ALL, (eventName, data) => {
console.log(eventName, data);
});
```
支持的事件类型如下,若想了解所有事件的详细情况,可以直接查看[示例项目源码中的 types.ts](https://github.com/coze-dev/coze-js/blob/main/packages/coze-js/src/ws-tools/types.ts)。
```TypeScript
// 事件监听示例
client.on(WsChatEventNames.ALL, (event) => {
console.log(`收到事件:`, event);
});
// 支持的事件类型
enum WsChatEventNames {
// 客户端基础事件
ALL = 'realtime.event', // 所有事件
CONNECTED = 'client.connected', // 客户端已连接
CONNECTING = 'client.connecting', // 客户端连接中
INTERRUPTED = 'client.interrupted', // 客户端已中断
DISCONNECTED = 'client.disconnected', // 客户端已断开
ERROR = 'client.error', // 客户端发生错误
// 音频控制事件
AUDIO_UNMUTED = 'client.audio.unmuted', // 音频已取消静音
AUDIO_MUTED = 'client.audio.muted', // 音频已静音
AUDIO_INPUT_DUMP = 'client.audio.input.dump', // 音频输入数据导出
// 设备变更事件
AUDIO_INPUT_DEVICE_CHANGED = 'client.input.device.changed', // 音频输入设备已改变
AUDIO_OUTPUT_DEVICE_CHANGED = 'client.output.device.changed', // 音频输出设备已改变
// 降噪控制事件
DENOISER_ENABLED = 'client.denoiser.enabled', // 降噪已启用
DENOISER_DISABLED = 'client.denoiser.disabled', // 降噪已禁用
// 服务端对话事件
CHAT_CREATED = 'server.chat.created', // 对话已创建
CHAT_UPDATED = 'server.chat.updated', // 对话已更新
// 会话状态事件
CONVERSATION_CHAT_CREATED = 'server.conversation.chat.created', // 会话对话已创建
CONVERSATION_CHAT_IN_PROGRESS = 'server.conversation.chat.in.progress', // 对话进行中
CONVERSATION_CHAT_COMPLETED = 'server.conversation.chat.completed', // 对话已完成
CONVERSATION_CHAT_FAILED = 'server.conversation.chat.failed', // 对话失败
CONVERSATION_CHAT_CANCELLED = 'server.conversation.chat.cancelled', // 对话已取消
CONVERSATION_CHAT_REQUIRES_ACTION = 'server.conversation.chat.requires_action', // 对话需要端插件响应
// 消息事件
CONVERSATION_MESSAGE_DELTA = 'server.conversation.message.delta', // 文本消息增量返回
CONVERSATION_MESSAGE_COMPLETED = 'server.conversation.message.completed', // 文本消息完成
// 音频事件
CONVERSATION_AUDIO_DELTA = 'server.conversation.audio.delta', // 语音消息增量返回
CONVERSATION_AUDIO_COMPLETED = 'server.conversation.audio.completed', // 语音回复完成
// 语音识别事件
CONVERSATION_AUDIO_TRANSCRIPT_UPDATE = 'server.conversation.audio_transcript.update', // 用户语音识别实时字幕更新
CONVERSATION_AUDIO_TRANSCRIPT_COMPLETED = 'server.conversation.audio_transcript.completed', // 用户语音识别完成
// 语音检测事件
INPUT_AUDIO_BUFFER_SPEECH_STARTED = 'server.input_audio_buffer.speech_started', // 检测到用户开始说话
INPUT_AUDIO_BUFFER_SPEECH_STOPPED = 'server.input_audio_buffer.speech_stopped', // 检测到用户停止说话
// 缓冲区事件
INPUT_AUDIO_BUFFER_COMPLETED = 'server.input_audio_buffer.completed', // 语音输入缓冲区提交完成
INPUT_AUDIO_BUFFER_CLEARED = 'server.input_audio_buffer.cleared', // 语音输入缓冲区已清除
// 其他事件
SERVER_ERROR = 'server.error', // 服务端错误
CONVERSATION_CLEARED = 'server.conversation.cleared', // 对话上下文已清除
DUMP_AUDIO = 'server.dump.audio' // 音频导出
}
```
### 步骤五:建立连接
在开始对话前,调用 `client.connect` 方法建立客户端和服务端之间的连接。
```TypeScript
try {
await client.connect();
} catch (error) {
console.log('连接失败', error);
}
```
* 连接过程可能因网络问题、权限问题或配置错误而失败,确保妥善处理异常。
* 连接成功后,麦克风会自动开始录音。若 `audioMutedDefault` 设置为 `true`,则会静音。
### 步骤六:对话控制
在对话过程中支持静音或取消静音、打断对话、发送文本消息。
* **静音/取消静音**
调用`setAudioEnable()` 方法静音或取消静音。该方法是一个异步方法,使用`await` 等待操作完成。在静音状态下,麦克风仍在工作,但不会发送音频数据。
```JavaScript
// 静音与取消静音
await client.setAudioEnable(false); // 静音
await client.setAudioEnable(true); // 取消静音
```
* **打断对话**
调用 `interrupt()` 方法打断当前对话,使智能体停止回复。
```JavaScript
// 打断对话
client.interrupt();
```
* **发送文本消息**
使用 `sendTextMessage()` 可以发送文本消息,而不是语音输入。
```JavaScript
// 发送文本消息
client.sendTextMessage("你好,我想了解一下天气情况");
```
### 步骤七:断开连接
调用 `disconnect()` 方法关闭连接并释放资源。如果需要重新开始对话,重新调用 `connect()` 方法建立连接。
```JavaScript
// 断开连接
await client.disconnect();
```
### 完整示例代码
完整的示例代码如下。你也可以参考[实时语音 WebSocket 示例源码](https://github.com/coze-dev/coze-js/tree/main/examples/realtime-websocket)获取更多示例代码。
```TypeScript
import {
WsChatEventNames,
WsChatClient,
WsToolsUtils,
} from '@coze/api/ws-tools';
// 初始化 client & 注册事件
const initClient = async () => {
// 检查语音设备权限
const result = await WsToolsUtils.checkDevicePermission();
if (!result.audio) {
throw new Error("需要麦克风访问权限");
}
// 初始化 client
const client = new WsChatClient({
token: "pat_Qm47PKJR5dvMOP53v6DyzwCbTtvEZHQc2TVINEveg9v1T3iSYlTdScJ8***",
botId: "your bot id",
allowPersonalAccessTokenInBrowser: true, // 可选:允许在浏览器中使用个人访问令牌
});
// 注册事件,一般在初始化 client 后设置
client.on(WsChatEventNames.ALL, (eventName, data) => {
console.log(eventName, data);
});
return client;
};
const handleConnect = async () => {
try {
const client = await initClient();
// 连接
await client.connect();
} catch (error) {
console.log("连接失败", error);
}
};
```
## 进阶功能
### 客户端配置
在初始化客户端时,你还可以进行高级配置,以满足不同的开发需求,包括:开启调试模式、指定智能体的音色、指定音频输入设备、音频处理及录制、AI 降噪、音频录制等。完整的配置项请查看[示例项目源码中的 types.ts](https://github.com/coze-dev/coze-js/blob/main/packages/coze-js/src/ws-tools/types.ts)。
```TypeScript
interface WsChatClientOptions {
// 必填项
token: GetToken; // Personal Access Token (PAT) 或 OAuth2.0 token,或获取 token 的函数
botId: string; // 智能体 ID
// 选填项
debug?: boolean; // 是否启用调试模式
headers?: Headers | Record; // 自定义请求头
allowPersonalAccessTokenInBrowser?: boolean; // 是否允许在浏览器环境中使用个人访问令牌
baseWsURL?: string; // WebSocket 基础 URL,默认为 wss://ws.coze.cn
websocketOptions?: WebsocketOptions; // WebSocket 配置选项
workflowId?: string; // 工作流 ID
voiceId?: string; // 音色 ID
deviceId?: string; // 音频输入设备 ID
// 音频相关配置
audioCaptureConfig?: {
noiseSuppression?: boolean; // 是否启用降噪
echoCancellation?: boolean; // 是否启用回声消除
autoGainControl?: boolean; // 是否启用自动增益控制
};
audioMutedDefault?: boolean; // 是否默认静音
// AI 降噪配置
aiDenoisingConfig?: {
mode?: AIDenoiserProcessorMode; // AI 降噪模式:NSNG(非平稳噪声抑制) 或 STATIONARY_NS(平稳噪声抑制)
level?: AIDenoiserProcessorLevel; // 降噪级别
assetsPath?: string; // AI 降噪 wasm 文件路径,默认为 '/external'
};
// 自定义音频流
mediaStreamTrack?: MediaStreamTrack;
// 音频录制配置(仅在 debug = true 时生效)
wavRecordConfig?: {
enableSourceRecord: boolean; // 是否启用源音频录制
enableDenoiseRecord: boolean; // 是否启用降噪后音频录制
};
}
```
### 音视频控制
在通话过程中,支持开启或关闭麦克风、设置输入音频设备。
* 开启或关闭麦克风
```TypeScript
// 开启/关闭麦克风
await client.setAudioEnable(true); // 开启麦克风
await client.setAudioEnable(false); // 关闭麦克风
```
* 设置输入音频设备
你可以通过` WsToolsUtils.getAudioDevices` 方法获取系统的音频输入和输出设备列表,返回的设备列表包含每个设备的 deviceId 和 label 信息。
```TypeScript
import { WsToolsUtils } from "@coze/realtime-api";
const devices = await WsToolsUtils.getAudioDevices(); // 获取输入、输出设备列表
client.setAudioInputDevice(devices.audioInputs[0].deviceId); // 设置音频输入设备
```
* 获取设备列表需要用户已授予麦克风权限。
* 在用户插入或移除设备后,应重新获取设备列表。
* 切换设备是异步操作,需要使用 await 等待完成。
* 如果指定的设备不可用,用户操作时将抛出异常。
### 开启或关闭调试模式
在调试模式下可以使用音频 dump 功能,以验证降噪效果。
1. 在创建 WsChatClient 时,将 `debug` 设置为 `true`,开启调试模式,并配置音频录制。
```Java
const client = new WsChatClient({
// ... 其他配置
debug: true, // 必须设置为 true,否则录制配置不生效
wavRecordConfig: {
enableSourceRecord: true, // 启用原始音频录制
enableDenoiseRecord: true, // 启用降噪后的音频录制
}
});
```
2. 监听音频 dump 事件来获取录制的音频数据。
```TypeScript
// 监听音频输入 dump 事件
client.on(WsChatEventNames.AUDIO_INPUT_DUMP, (eventName, event) => {
// event.data 包含:
// - name: string 文件名
// - wav: Blob 音频数据(WAV格式)
const { name, wav } = event.data;
console.log(`收到音频dump,文件名: ${name}`);
// 可以将 wav 数据保存为文件
const url = URL.createObjectURL(wav);
const a = document.createElement('a');
a.href = url;
a.download = name;
a.click();
});
```
dump 功能会产生两种音频文件:
* 原始音频文件:包含用户的原始输入音频。只有当 `enableSourceRecord = true` 时才会生成原始音频文件。
* 降噪后音频文件:包含经过降噪处理后的音频。只有当 `enableDenoiseRecord = true` 时才会生成降噪后音频文件。
### AI 降噪
* 降噪处理可能增加 CPU 使用率,在低性能设备上可能影响体验。
* 不同的降噪等级会影响音频质量和降噪效果。
1. 检查浏览器是否支持 AI 降噪。
某些浏览器或设备可能不支持全部降噪功能,当不确定设备支持情况时,可以使用 `WsToolsUtils.checkDenoiserSupport() `方法检查。
```TypeScript
const denoiserSupport = await WsToolsUtils.checkDenoiserSupport();
if (!denoiserSupport) {
console.warn("当前浏览器不支持 AI 降噪");
}
```
2. 在初始化时配置 AI 降噪。
```TypeScript
const client = new WsChatClient({
// 其它配置
aiDenoisingConfig: {
mode: 'NSNG', // AI 降噪模式,包括NSNG(非平稳噪声抑制) 或 STATIONARY_NS(平稳噪声抑制)
level: 'SOFT', // 降噪等级,包括SOFT(舒缓降噪), AGGRESSIVE(激进降噪。将降噪强度提高到激进降噪会增大损伤人声的概率。)
}
});
```
3. 开启或关闭 AI 降噪,设置 AI 降噪的等级和模式。
```TypeScript
// 设置降噪开关
client.setDenoiserEnabled(true);
// 设置降噪等级
client.setDenoiserLevel("SOFT"); // 可选值: SOFT(舒缓降噪), AGGRESSIVE(激进降噪。将降噪强度提高到激进降噪会增大损伤人声的概率。)
// 设置降噪模式
client.setDenoiserMode("NSNG"); // NSNG(非平稳噪声抑制) 或 STATIONARY_NS(平稳噪声抑制)
```
### 配置音色
在初始化 WsChat SDK 时,你可以通过指定 `voiceId` 来自定义智能体在对话中使用的音色。以下是使用说明:
1. 获取可用的音色 ID。
你可以通过[查看音色列表](https://docs.coze.cn/api/open/docs/developer_guides/list_voices) 获取可用的音色列表。
```TypeScript
import { CozeAPI, COZE_CN_BASE_URL } from '@coze/api';
const api = new CozeAPI({
token: 'your-access-token',
baseURL: COZE_CN_BASE_URL,
});
// 获取可用的音色列表
const voices = await api.audio.voices.list();
```
2. 在初始化 WsChat 客户端时,指定智能体使用的音色。
每个音色都有不同的特征,如性别、语言、风格等,如果不指定 `voiceId` 或值为空,将使用默认的`柔美女友`音色,音色 ID 为 7426720361733046281。
```TypeScript
import { WsChatClient } from "@coze/api/ws-tools";
const client = new WsChatClient({
// 其它配置
voiceId: "7426720361733046281",
});
```
## WebSocket 事件
### 基本概念
* 上行事件:设备端向服务端发送的请求,如提交插件执行结果、更新对话配置等。
* 下行事件:服务端向设备端发送的通知,如端插件请求、对话状态变化等。
* 会话与对话:会话是用户与智能体的一次完整交互,对话是会话中的一次具体调用。
* 事件 ID:每个事件应有唯一 ID,便于问题定位。
### 事件的使用流程
信令事件的使用流程如下:
1. 初始化。通过监听 `chat.created` 事件,确认对话初始化完成。
2. 发送请求。使用上行事件(如 `conversation.message.create`)向智能体发送消息。
3. 处理响应。监听下行事件(如 `conversation.message.delta`)获取智能体的增量回复。
4. 插件交互。在收到事件 `conversation.chat.requires_action` 后,执行插件操作并通过事件 `conversation.chat.submit_tool_outputs` 提交结果。根据需求选择 blocking 或 nonblocking 模式,控制插件执行是否阻塞对话。
5. 错误处理。通过监听 `error` 事件捕获和处理异常情况。
使用示例如下:
```TypeScript
import { WebsocketsEventType, RoleType } from '@coze/api';
// 使用示例
client.sendMessage({
"id": "1",
"event_type": WebsocketsEventType.CONVERSATION_MESSAGE_CREATE,
"data": {
"role": RoleType.User,
"content_type": "text",
"content": "你好"
}
});
```
###